
-
 chevron_right
chevron_right
Large language models also work for protein structures
news.movim.eu / ArsTechnica · Thursday, 16 March, 2023 - 19:01 · 1 minute

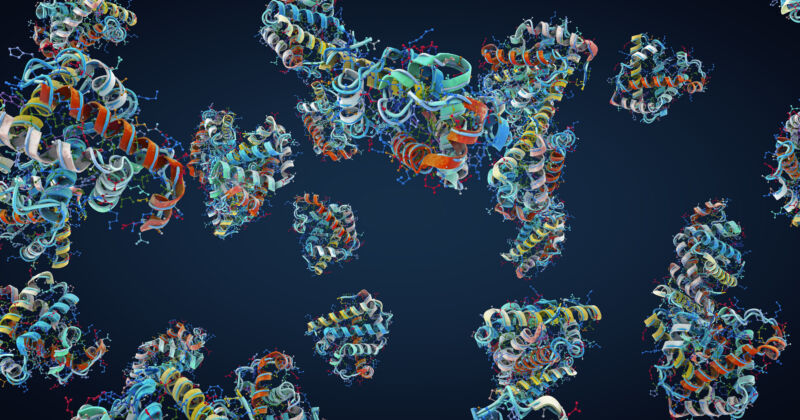
Enlarge (credit: CHRISTOPH BURGSTEDT/SCIENCE PHOTO LIBRARY )
{kind=link}
The success of ChatGPT and its competitors is based on what's termed emergent behaviors. These systems, called large language models (LLMs), weren't trained to output natural-sounding language (or effective malware ); they were simply tasked with tracking the statistics of word usage. But, given a large enough training set of language samples and a sufficiently complex neural network, their training resulted in an internal representation that "understood" English usage and a large compendium of facts. Their complex behavior emerged from a far simpler training.
A team at Meta has now reasoned that this sort of emergent understanding shouldn't be limited to languages. So it has trained an LLM on the statistics of the appearance of amino acids within proteins and used the system's internal representation of what it learned to extract information about the structure of those proteins. The result is not quite as good as the best competing AI systems for predicting protein structures, but it's considerably faster and still getting better.
LLMs: Not just for language
The first thing you need to know to understand this work is that, while the term "language" in the name "LLM" refers to their original development for language processing tasks, they can potentially be used for a variety of purposes. So, while language processing is a common use case for LLMs, these models have other capabilities as well. In fact, the term "Large" is far more informative, in that all LLMs have a large number of nodes—the "neurons" in a neural network—and an even larger number of values that describe the weights of the connections among those nodes. While they were first developed to process language, they can potentially be used for a variety of tasks.