-
chevron_right
Michael Meeks: 2025-03-25 Tuesday
news.movim.eu / PlanetGnome • 25 March
0
mic_none No sound detected from your microphone

Michael Meeks: 2025-03-25 Tuesday
news.movim.eu / PlanetGnome • 25 March
news.movim.eu / PlanetGnome • 1 March
Joaquim Rocha: A minha avó
Felipe Borges: Time to write proposals for GSoC 2025 with GNOME!
news.movim.eu / PlanetGnome • 24 January

It is that time of the year again when we start gathering ideas and mentors for Google Summer Code .
@ Mentors , please submit new proposals in our Project ideas GitLab repository before the end of January.
Proposals will be reviewed by the GNOME GSoC Admins and posted in https://gsoc.gnome.org/2025 when approved.
If you have any doubts, please don’t hesitate to contact the GNOME Internship Committee.
Adetoye Anointing: Extracting Texts And Elements From SVG2
news.movim.eu / PlanetGnome • 23 January • 3 minutes
Have you ever wondered how SVG files render complex text layouts with different styles and directions so seamlessly? At the core of this magic lies text layout algorithms—an essential component of SVG rendering that ensures text appears exactly as intended.
Text layout algorithms are vital for rendering SVGs that include styled or bidirectional text. However, before layout comes text extraction —the process of collecting and organizing text content and properties from the XML tree to enable accurate rendering.
SVGs, being XML-based formats, resemble a tree-like structure similar to HTML. To extract information programmatically, you navigate through nodes in this structure.
Each node in the XML tree holds critical details for implementing the SVG2 text layout algorithm, including:
Bidi-control refers to managing text direction (e.g., Left-to-Right or Right-to-Left) using special Unicode characters. This is crucial for accurately displaying mixed-direction text, such as combining English and Arabic.
<text> foo <tspan>bar</tspan> baz </text>
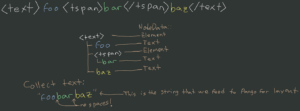
The diagram and code sample shows the structure librsvg creates when it parses this XML tree.
Here, the <text> element has three children:
When traversed programmatically, the extracted text from this structure would be “foobarbaz”.
To extract text from the XML tree:
While this example seems straightforward, real-world SVG2 files introduce additional complexities, such as bidi-control and styling, which must be handled during text extraction.
Real-world examples often involve more than just plain text nodes. Let’s examine a more complex XML tree that includes styling and bidi-control:
Example:
<text> "Hello" <tspan font-style="bold;">bold</tspan> <tspan direction="rtl" unicode-bidi="bidi-override">مرحبا</tspan> <tspan font-style="italic;">world</tspan> </text>
 credit: Federico (my mentor)
credit: Federico (my mentor)
In this example, the <text> element has four children:
This structure introduces challenges, such as:
Programmatically extracting text from such structures involves traversing nodes, identifying relevant attributes, and aggregating the text and bidi-control characters accurately.
One significant insight during development was the use of Test-Driven Development (TDD) , thanks to my mentor Federico. Writing tests before implementation made it easier to visualize and address complex scenarios. This approach turned what initially seemed overwhelming into manageable steps, leading to robust and reliable solutions.
Text extraction is the foundational step in implementing the SVG2 text layout algorithm. By effectively handling complexities such as bidi-control and styling, we ensure that SVGs render text accurately and beautifully, regardless of direction or styling nuances.
If you’ve been following my articles and feel inspired to contribute to librsvg or open source projects, I’d love to hear from you! Drop a comment below to share your thoughts, ask questions, or offer insights. Your contributions—whether in the form of questions, ideas, or suggestions—are invaluable to both the development of librsvg and the ongoing discussion around SVG rendering.

In my next article, we’ll explore how these extracted elements are processed and integrated into the text layout algorithm. Stay tuned—there’s so much more to uncover!
Sonny Piers: Workbench News
news.movim.eu / PlanetGnome • 28 May, 2024
Workbench is now available on the GNOME nightly repository .
Please prefer Workbench from Flathub but if you're a GNOME contributor, Workbench nightly can come handy
flatpak remote-add --if-not-exists gnome-nightly https://nightly.gnome.org/gnome-nightly.flatpakrepo
flatpak install gnome-nightly re.sonny.Workbench.Devel
It is the first app on GitHub to be available on GNOME nightly. Thanks to Jordan Petridis and Bilal Elmoussaoui for the help.
I'm very happy to announce that as of yesterday we are mentoring 2 students on Workbench.
Angelo Verlain (aka vixalien) is a student from Kigali, Rwanda. Angelo is already a GNOME Foundation member and made significant contributions including an audio player app “Decibels” that is being incubated to join GNOME core apps .
Bharat Tyagi is a student from Jaipur, India. Bharat made great contributions to Workbench during the GSoC contribution period, and I'm looking forward to seeing more of it. You can read their introduction here .
Angelo is working on TypeScript support in Workbench and GNOME.
Bharat is working on porting remaining demos to Vala, redesigning the Library and add code search to it.
Very happy working with both of them
Felipe Borges: GNOME will have two Outreachy interns conducting a series of short user research exercises
news.movim.eu / PlanetGnome • 28 May, 2024
Andy Wingo: cps in hoot
news.movim.eu / PlanetGnome • 27 May, 2024 • 10 minutes
Good morning good morning! Today I have another article on the Hoot Scheme-to-Wasm compiler , this time on Hoot’s use of the continuation-passing-style (CPS) transformation.
So, just a bit of context to start out: Hoot is a Guile, Guile is a Scheme, Scheme is a Lisp, one with “proper tail calls” : function calls are either in tail position, syntactically, in which case they are tail calls , or they are not in tail position, in which they are non-tail calls . A non-tail call suspends the calling function, putting the rest of it (the continuation ) on some sort of stack, and will resume when the callee returns. Because non-tail calls push their continuation on a stack, we can call them push calls .
(define (f) ;; A push call to g, binding its first return value. (define x (g)) ;; A tail call to h. (h x))
Usually the problem in implementing Scheme on other language run-times comes in tail calls, but WebAssembly supports them natively (except on JSC / Safari; should be coming at some point though). Hoot’s problem is the reverse: how to implement push calls?
The issue might seem trivial but it is not. Let me illustrate briefly by describing what Guile does natively (not compiled to WebAssembly). Firstly, note that I am discussing residual push calls, by which I mean to say that the optimizer might remove a push call in the source program via inlining: we are looking at those push calls that survive the optimizer. Secondly, note that native Guile manages its own stack instead of using the stack given to it by the OS; this allows for push-call recursion without arbitrary limits. It also lets Guile capture stack slices and rewind them , which is the fundamental building block we use to implement exception handling, Fibers and other forms of lightweight concurrency.
The straightforward function call will have an artificially limited total recursion depth in most WebAssembly implementations, meaning that many idiomatic uses of Guile will throw exceptions. Unpleasant, but perhaps we could stomach this tradeoff. The greater challenge is how to slice the stack. That I am aware of, there are three possible implementation strategies.
One possibility is that the platform provides a generic, powerful stack-capture primitive, which is what Guile does. The good news is that one day, the WebAssembly stack-switching proposal should provide this too. And in the meantime, the so-called JS Promise Integration (JSPI) proposal gets close: if you enter Wasm from JS via a function marked as async, and you call out to JavaScript to a function marked as async (i.e. returning a promise), then on that nested Wasm-to-JS call, the engine will suspend the continuation and resume it only when the returned promise settles (i.e. completes with a value or an exception). Each entry from JS to Wasm via an async function allocates a fresh stack, so I understand you can have multiple pending promises, and thus multiple wasm coroutines in progress. It gets a little gnarly if you want to control when you wait, for example if you might want to wait on multiple promises; in that case you might not actually mark promise-returning functions as async, and instead import an async-marked async function waitFor(p) { return await p} or so, allowing you to use Promise.race and friends. The main problem though is that JSPI is only for JavaScript. Also, its stack sizes are even smaller than the the default stack size.
So much for generic solutions. There is another option, to still use push calls from the target machine (WebAssembly), but to transform each function to allow it to suspend and resume. This is what I think of as Joe Marshall’s stack trick (also see §4.2 of the associated paper ). The idea is that although there is no primitive to read the whole stack, each frame can access its own state. If you insert a try / catch around each push call, the catch handler can access local state for activations of that function. You can slice a stack by throwing a SaveContinuation exception, in which each frame’s catch handler saves its state and re-throws. And if we want to avoid exceptions, we can use checked returns as Asyncify does.
I never understood, though, how you resume a frame. The Generalized Stack Inspection paper would seem to indicate that you need the transformation to introduce a function to run “the rest of the frame” at each push call, which becomes the Invoke virtual method on the reified frame object. To avoid code duplication you would have to make normal execution flow run these Invoke snippets as well, and that might undo much of the advantages. I understand the implementation that Joe Marshall was working on was an interpreter, though, which bounds the number of sites needing such a transformation.
The third option is a continuation-passing-style transformation. A CPS transform results in a program whose procedures “return” by tail-calling their “continuations”, which themselves are procedures. Taking our previous example, a naïve CPS transformation would reify the following program:
(define (f' k) (g' (lambda (x) (h' k x))))
Here f' (“f-prime”) receives its continuation as an argument. We call g' , for whose continuation argument we pass a closure. That closure is the return continuation of g , binding a name to its result, and then tail-calls h with respect to f . We know their continuations are the same because it is the same binding, k .
Unfortunately we can’t really slice abitrary ranges of a stack with the naïve CPS transformation: we can only capture the entire continuation, and can’t really inspect its structure. There is also no way to compose a captured continuation with the current continuation. And, in a naïve transformation, we would be constantly creating lots of heap allocation for these continuation closures; a push call effectively pushes a frame onto the heap as a closure, as we did above for g' .
There is also the question of when to perform the CPS transform; most optimizing compilers would like a large first-order graph to work on, which is out of step with the way CPS transformation breaks functions into many parts. Still, there is a nugget of wisdom here. What if we preserve the conventional compiler IR for most of the pipeline, and only perform the CPS transformation at the end? In that way we can have nice SSA-style optimizations. And, for return continuations of push calls, what if instead of allocating a closure, we save the continuation data on an explicit stack. As Andrew Kennedy notes , closures introduced by the CPS transform follow a stack discipline, so this seems promising; we would have:
(define (f'' k)
(push! k)
(push! h'')
(g'' (lambda (x)
(define h'' (pop!))
(define k (pop!))
(h'' k x))))
The explicit stack allows for generic slicing, which makes it a win for implementing delimited continuations.
Hoot takes the CPS transformation approach with stack-allocated return closures. In fact, Hoot goes a little farther, too far probably:
(define (f''')
(push! k)
(push! h''')
(push! (lambda (x)
(define h'' (pop!))
(define k (pop!))
(h'' k x)))
(g'''))
Here instead of passing the continuation as an argument, we pass it on the stack of saved values. Returning pops off from that stack; for example, (lambda () 42) would transform as (lambda () ((pop!) 42)) . But some day I should go back and fix it to pass the continuation as an argument, to avoid excess stack traffic for leaf function calls.
There are some gnarly details though, which I know you are here for!
For our function f , we had to break it into two pieces: the part before the push-call to g and the part after. If we had two successive push-calls, we would instead split into three parts. In general, each push-call introduces a split; let us use the term tails for the components produced by a split. (You could also call them continuations .) How many tails will a function have? Well, one for the entry, one for each push call, and one any time control-flow merges between two tails. This is a fixpoint problem, given that the input IR is a graph. (There is also some special logic for call-with-prompt but that is too much detail for even this post.)
Guile is a dynamically-typed language, having a uniform SCM representation for every value. However in the compiler and run-time we can often unbox some values, generally as u64 / s64 / f64 values, but also raw pointers of some specific types, some GC-managed and some not. In native Guile, we can just splat all of these data members into 64-bit stack slots and rely on the compiler to emit stack maps to determine whether a given slot is a double or a tagged heap object reference or what. In WebAssembly though there is no sum type, and no place we can put either a u64 or a (ref eq) value. So we have not one stack but three (!) stacks: one for numeric values, implemented using a Wasm memory; one for (ref eq) values, using a table ; and one for return continuations, because the func type hierarchy is disjoin from eq . It’s.... it’s gross? It’s gross.
Before a push-call, you save any local variables that will be live after the call. This is also a flow analysis problem. You can leave off constants, and instead reify them anew in the tail continuation.
I realized, though, that we have some pessimality related to stacked continuations. Consider:
(define (q x) (define y (f)) (define z (f)) (+ x y z))
Hoot’s CPS transform produces something like:
(define (q0 x) (save! x) (save! q1) (f)) (define (q1 y) (restore! x) (save! x) (save! y) (save! q2) (f)) (define (q2 z) (restore! x) (restore! y) ((pop!) (+ x y z)))
So q0 saved x , fine, indeed we need it later. But q1 didn’t need to restore x uselessly, only to save it again on q2 ‘s behalf. Really we should be applying a stack discipline for saved data within a function. Given that the source IR is a graph, this means another flow analysis problem, one that I haven’t thought about how to solve yet. I am not even sure if there is a solution in the literature, given that the SSA-like flow graphs plus tail calls / CPS is a somewhat niche combination.
The continuations introduced by CPS transformation have associated calling conventions: return continuations may have the generic varargs type, or the compiler may have concluded they have a fixed arity that doesn’t need checking. In any case, for a return, you call the return continuation with the returned values, and the return point then restores any live-in variables that were previously saved. But for a merge between tails, you can arrange to take the live-in variables directly as parameters; it is a direct call to a known continuation, rather than an indirect call to an unknown call site.
Guile’s intermediate representation is called CPS soup , and you might wonder what relationship that CPS has to this CPS. The answer is not much. The continuations in CPS soup are first-order; a term in one function cannot continue to a continuation in another function. (Inlining and contification can merge graphs from different functions, but the principle is the same.)
It might help to explain that it is the same relationship as it would be if Guile represented programs using SSA: the Hoot CPS transform runs at the back-end of Guile’s compilation pipeline, where closures representations have already been made explicit. The IR is still direct-style, just that syntactically speaking, every call in a transformed program is a tail call. We had to introduce save and restore primitives to implement the saved variable stack, and some other tweaks, but generally speaking, the Hoot CPS transform ensures the run-time all-tail-calls property rather than altering the compile-time language; a transformed program is still CPS soup.
Did we actually make the right call in going for a CPS transformation?
I don’t have good performance numbers at the moment, but from what I can see, the overhead introduced by CPS transformation can impose some penalties, even 10x penalties in some cases. But some results are quite good, improving over native Guile, so I can’t be categorical.
But really the question is, is the performance acceptable for the functionality , and there I think the answer is more clear: we have a port of Fibers that I am sure Spritely colleagues will be writing more about soon, we have good integration with JavaScript promises while not relying on JSPI or Asyncify or anything else, and we haven’t had to compromise in significant ways regarding the source language. So, for now, I am satisfied, and looking forward to experimenting with the stack slicing proposal as it becomes available.
Until next time, happy hooting!
Andy Wingo: hoot's wasm toolkit
news.movim.eu / PlanetGnome • 24 May, 2024 • 5 minutes
Good morning! Today we continue our dive into the Hoot Scheme-to-WebAssembly compiler . Instead of talking about Scheme, today let’s focus on WebAssembly, specifically the set of tools that we have built in Hoot to wrangle Wasm. I think it’s neat, but I have a story to push as well: if you compile to Wasm, probably you should write a low-level Wasm toolchain as well.
(Incidentally, some of this material was taken from a presentation I gave to the Wasm standardization organization back in October , which I think I haven’t shared yet in this space, so if you want some more context, have at it.)
Compilers are all about names: definitions of globals, types, local variables, and so on. An intermediate representation in a compiler is a graph of definitions and uses in which the edges are names, and the set of possible names is generally unbounded; compilers make more names when they see fit, for example when copying a subgraph via inlining, and remove names if they determine that a control or data-flow edge is not necessary. Having an unlimited set of names facilitates the graph transformation work that is the essence of a compiler.
Machines, though, generally deal with addresses, not names; one of the jobs of the compiler back-end is to tabulate the various names in a compilation unit, assigning them to addresses, for example when laying out an ELF binary. Some uses may refer to names from outside the current compilation unit, as when you use a function from the C library. The linker intervenes at the back-end to splice in definitions for dangling uses and applies the final assignment of names to addresses.
When targetting Wasm, consider what kinds of graph transformations you would like to make. You would probably like for the compiler to emit calls to functions from a low-level run-time library written in wasm . Those functions are probably going to pull in some additional definitions, such as globals, types, exception tags, and so on. Then once you have your full graph, you might want to lower it, somehow: for example, you choose to use the stringref string representation, but browsers don’t currently support it; you run a post-pass to lower to UTF-8 arrays, but then all your strings are not constant , meaning they can’t be used as global initializers; so you run another post-pass to initialize globals in order from the start function . You might want to make other global optimizations as well, for example to turn references to named locals into unnamed stack operands (not yet working :).
Anyway what I am getting at is that you need a representation for Wasm in your compiler, and that representation needs to be fairly complete. At the very minimum, you need a facility to transform that in-memory representation to the standard WebAssembly text format , which allows you to use a third-party assembler and linker such as Binaryen’s wasm-opt . But since you have to have the in-memory representation for your own back-end purposes, probably you also implement the names-to-addresses mapping that will allow you to output binary WebAssembly also. Also it could be that Binaryen doesn’t support something you want to do; for example Hoot uses block parameters , which are supported fine in browsers but not in Binaryen .
(I exaggerate a little; Binaryen is a more reasonable choice now than it was before the GC proposal was stabilised. But it has been useful to be able to control Hoot’s output, for example as the exception-handling proposal has evolved.)
Once you have a textual and binary writer, and an in-memory representation, perhaps you want to be able to read binaries as well; and perhaps you want to be able to read text. Reading the text format is a little annoying, but I had implemented it already in JavaScript a few years ago; and porting it to Scheme was a no-brainer, allowing me to easily author the run-time Wasm library as text.
And so now you have the beginnings of a full toolchain, built just out of necessity: reading, writing, in-memory construction and transformation. But how are you going to test the output? Are you going to require a browser? That’s gross. Node? Sure, we have to check against production Wasm engines, and that’s probably the easiest path to take; still, would be nice if this were optional. Wasmtime? But that doesn’t do GC.
No, of course not, you are a dirty little compilers developer, you are just going to implement a little wasm interpreter, aren’t you. Of course you are. That way you can build nice debugging tools to help you understand when things go wrong. Hoot’s interpreter doesn’t pretend to be high-performance—it is not—but it is simple and it just works. Massive kudos to Spritely hacker David Thompson for implementing this. I think implementing a Wasm VM also had the pleasant side effect that David is now a Wasm expert; implementation is the best way to learn.
Finally, one more benefit of having a Wasm toolchain as part of the compiler: %inline-wasm . In my example from last time, I had this snippet that makes a new bytevector:
(%inline-wasm
'(func (param $len i32) (param $init i32)
(result (ref eq))
(struct.new
$mutable-bytevector
(i32.const 0)
(array.new $raw-bytevector
(local.get $init)
(local.get $len))))
len init)
%inline-wasm takes a literal as its first argument, which should parse as a Wasm function. Parsing guarantees that the wasm is syntactically valid, and allows the arity of the wasm to become apparent: we just read off the function’s type. Knowing the number of parameters and results is one thing, but we can do better, in that we also know their type, which we use for intentional types , requiring in this case that the parameters be exact integers which get wrapped to the signed i32 range. The resulting term is spliced into the CPS graph , can be analyzed for its side effects , and ultimately when written to the binary we replace each local reference in the Wasm with a reference of the appropriate local variable . All this is possible because we have the tools to work on Wasm itself.
Hoot’s Wasm toolchain is about 10K lines of code, and is fairly complete. I think it pays off for Hoot. If you are building a compiler targetting Wasm, consider budgetting for a 10K SLOC Wasm toolchain; you won’t regret it.
Next time, an article on Hoot’s use of CPS. Until then, happy hacking!
Justin W. Flory: Outreachy May 2024: A letter to Fedora applicants
news.movim.eu / PlanetGnome • 2 May, 2024 • 3 minutes

The post Outreachy May 2024: A letter to Fedora applicants appeared first on /home/jwf/ .
/home/jwf/ - Free & Open Source, technology, travel, and life reflections
To all Outreachy May 2024 applicants to the Fedora Project ,
Today is May 2nd, 2024. The Outreachy May 2024 round results will be published in a few short hours. This year, the participation in Fedora for Outreachy May 2024 was record-breaking. Fedora will fund three internships this year. During the application and contribution phase, over 150 new contributors appeared in our Mentored Project contribution channels. For the project I am mentoring specifically, 38 applicants recorded contributions and 33 applicants submitted final applications. This is my third time mentoring, but this Outreachy May 2024 round has been a record-breaker for all the projects I have mentored until now.
But breaking records is not what this letter is about.
This day can be either enormously exciting and enormously disappointing. It is a tough day for me. There are so many Outreachy applicants who are continuing to contribute after the final applications were due. I see several applicants from my project who are contributing across the Fedora community, and actually leveling up to even bigger contributions than the application period. It is exciting to see people grow in their confidence and capabilities in an Open Source community like Fedora. Mentoring is a rewarding task for me, and I feel immensely proud of the applicants we have had in the Fedora community this round.
But the truth is difficult. Fedora has funding for three interns, hard and simple. Hard decisions have to be made. If I had unlimited funding, I would have hired so many of our applicants. But funding is not unlimited. Three people will receive great news today, and most people will receive sad news. Throughout this entire experience in the application phase, I wanted to design me and Joseph Gayoso’s project so that even folks who were not selected would have an enriching experience. We wanted to put something real in the hands of our applicants at the end. We also wanted to boost their confidence in showing up in a community and guide them on how to roll up your sleeves and get started. Looking at the portfolios that applicants to our project submitted, I admire how far our applicants came since the day that projects were announced. Most applicants never participated in an open source community before. And for some, you would never have known that either!
So, if you receive the disappointing news today, remember that it does not reflect badly on you. The Outreachy May 2024 round was incredibly competitive. Literally , record-breaking. We have to say no to many people who have proved that they have what it takes to be a capable Fedora Outreachy intern. I hope you can look at all the things you learned and built over these past few months, and use this as a step-up to the next opportunity awaiting you. Maybe it is an Outreachy internship in a future round, or maybe it is something else. If there is anything I have learned, it is that life takes us on the most unexpected journeys sometimes. And whatever is meant to happen, will happen. I believe that there is a reason for everything, but we may not realize what that reason is until much later in the future.
Thank you to all of the Fedora applicants who put in immense effort over the last several months. I understand if you choose to stop contributing to Fedora. I hope that you will not be discouraged from open source generally though, and that you will keep trying. If you do choose to continue contributing to Fedora, I promise we will find a place for you to continue on. Regardless of your choice in contributing, keep shining and be persistent. Don’t give up easily, and remember that what you learned in these past few months can give a leading edge on that next opportunity waiting around the corner for you.
Freedom, Friends, Features, First!
— Justin