
-
chevron_right
Georges Basile Stavracas Neto: 2023 in retrospect
news.movim.eu / PlanetGnome • 12 January, 2024 • 13 minutes

2023 was a crushing year. It just slipped away, I barely managed to process all that happened. After going full offline for a very short 4-day break last week, I noticed I simply couldn’t remember most of the events that happened last year.
We’re in 2024 now, and to start the year afresh, I think it’ll be a good exercise to list all relevant personal and work achievements accomplished last year.
Portals

The work that happened on portals during 2023 is going to be hard to summarize in this small space. I’m writing a lengthier article about it, it’s quite a lot.
What is worth mentioning is that, thanks to the Sovereign Tech Fund grant for GNOME , I’ve been able to explore a new USB portal for enabling devices to be available to the sandbox.
I’ve used this opportunity to also go through the rather large backlog of maintenance tasks. More than 80 obsoleted issues were purged from the issue tracker; a proper place for discussions, questions, and suggestions was set up; documentation was entirely redone and is in a much better state now; a variety of bugs was fixed.
The big highlights were the new website, and documentation. Thanks to Jakub , we have stunning pixel art in the the website and the documentation pages. Thanks to Emmanuele , documentation was moved to Sphinx and restructured.
The new website doesn’t have a domain of its own, but you can find it here . The documentation pages can be found here .
On the GNOME side, I’ve fixed a variety of bugs in xdg-desktop-portal-gnome, and merged a few smaller UI improvements. Nothing major, but things keep improving.
Calendar

The main highlight of 2023 for Calendar was of course the new infinitely scrolling month view. It took quite a long time to get that done – I think it took me about 3 months of low bandwidth work, in parallel to my day job – but the result seems more than worth the effort. It made Jeff and Skelly happy as well, and that’s the big reward to me.
But what was truly fantastic was to see more contributors coming to Calendar and helping fixing bugs, update the various corners of the codebase to use modern libadwaita widgets, triage issues and put the issue tracker in a good shape, and more.
Settings
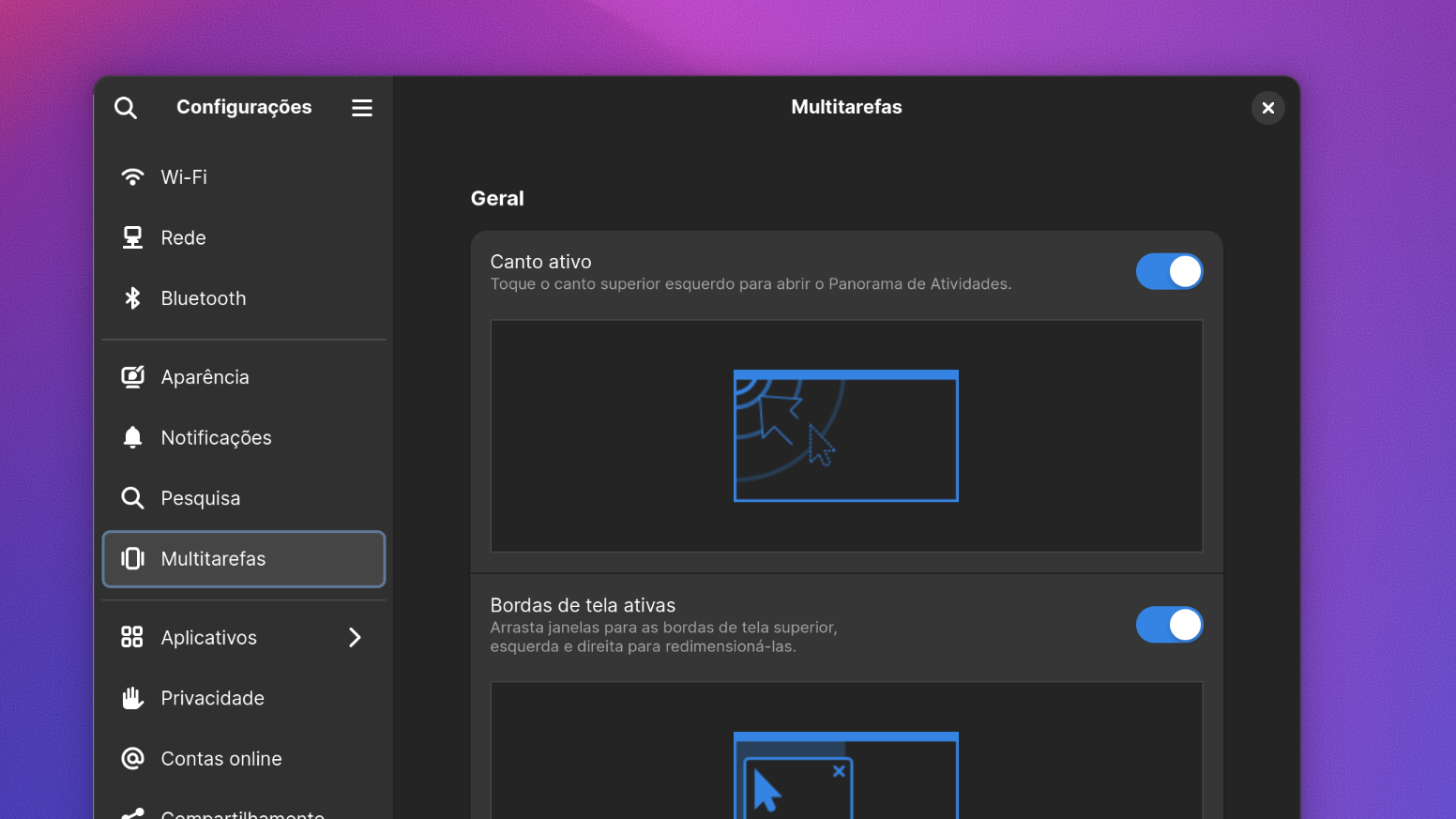
Sadly 2023 was the year I resigned from maintainership duties of GNOME Settings. I was not feeling any pleasure on working on it anymore, and given the controversial nature of the app, the high amount of stress was simply too much to handle in my personal time. I was able to review a variety of merge requests before resigning.
Fortunately, Felipe Borges stepped up to fill that role and is doing a fantastic job in there. I think the project is in much better and more capable hands now.
GTK
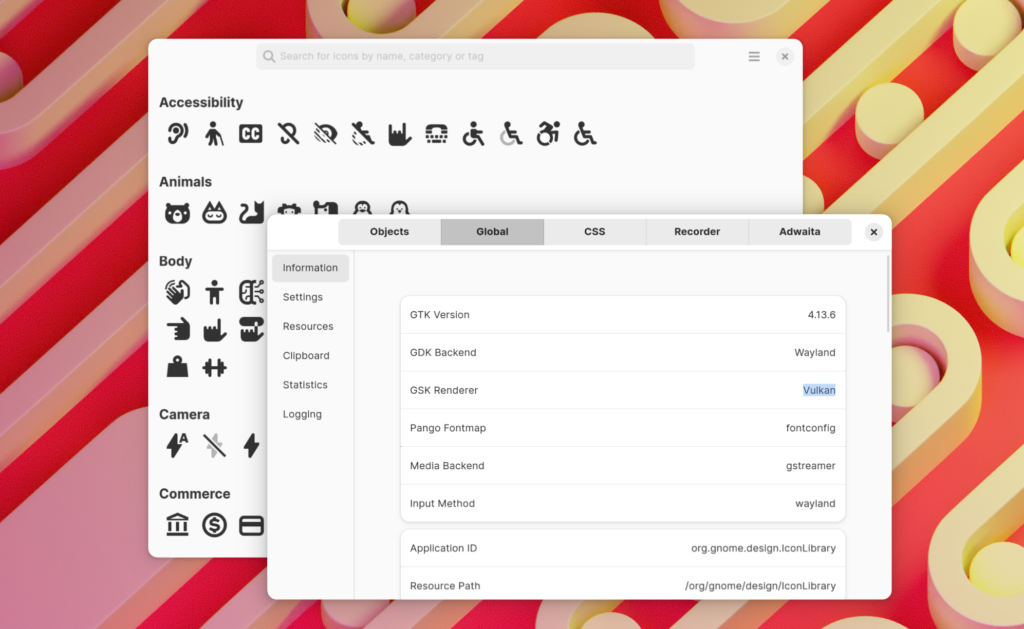
Back in April, my interest in the Vulkan renderer peaked again, so I built and tested it. Sadly it was in a poor state. After a few rounds of bug fixes , the Vulkan renderer was in a working state once again – although many render ops weren’t implemented, like shadows, which made things slow.
Shortly after, Benjamin began working on the new unified renderer that was merged just last week, which largely solves the Vulkan drawbacks. This is very exciting.
Mutter & Shell

My involvement with Mutter & Shell was not as high as it used to, and it’s mostly focused on code reviews and discussing releases and features. However, I did manage to get a few interesting things done in 2023.
The most notable one is probable the new workspace activities indicator:

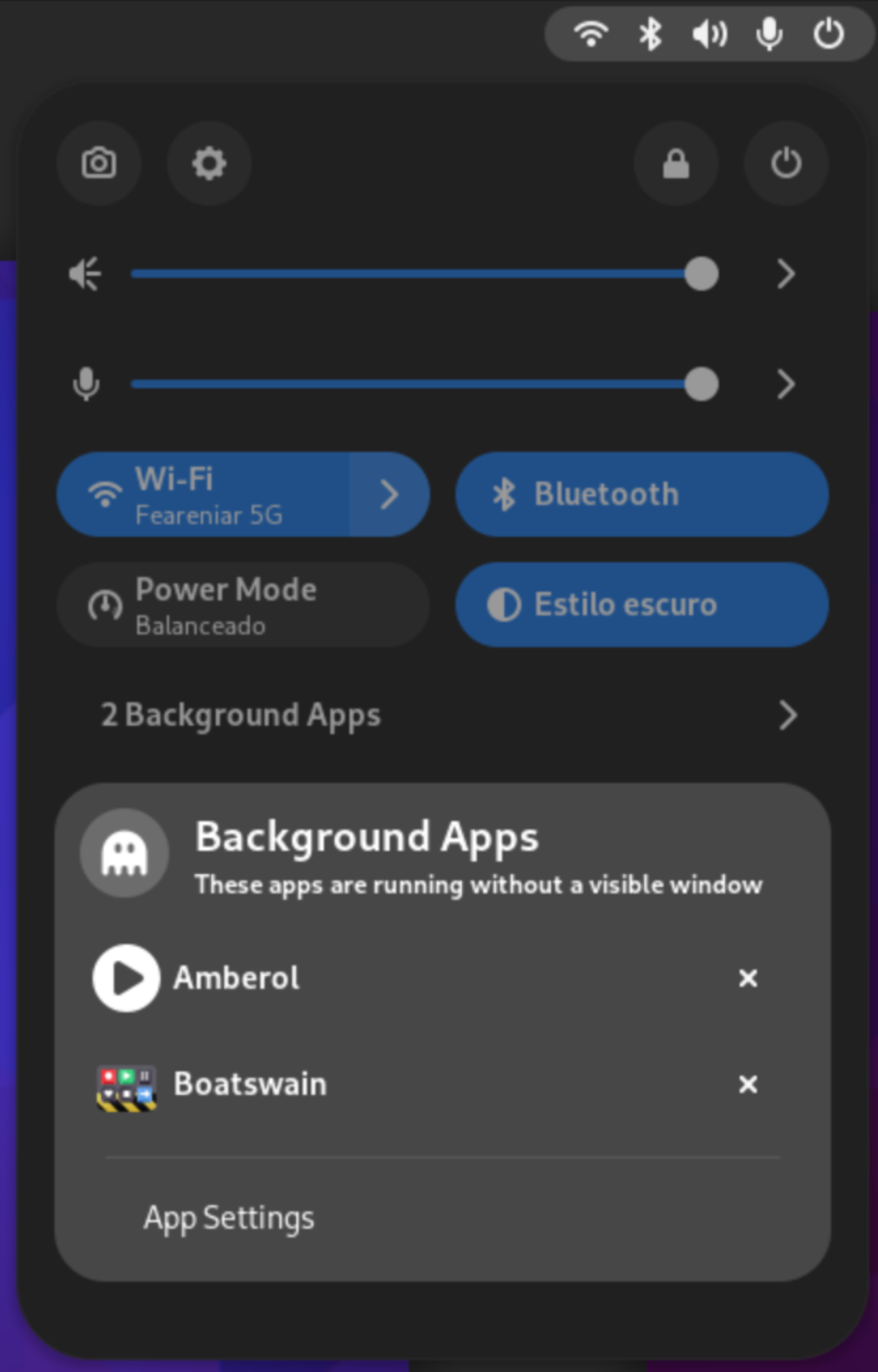
Another interesting feature that landed on GNOME Shell that I’ve worked on, featuring XDG Desktop Portal, is the background apps monitor:
On Mutter side, I’ve been mostly focused on improving screencasting support. More than 30 patches related to that were merged. It’s not something I can slap a fancy screenshot here, but YaLTeR ‘s profiling shows that these improvements made screencasting 5~9x faster on the most common cases.
Software

In the first quarter of 2023, thanks to the Endless OS Foundation who allowed me to work on it, I was able to investigate and fix one big performance issue in GNOME Software that affected the perceived fluidity of the app.
You can see how noticeable the difference is in this video:
I wrote a lengthier article explaining the whole situation, you can read more about it here .
Boatswain

Boatswain, my little app to control Elgato Stream Deck devices, saw 2 new releases packed with nice new features and new actions.
Thanks to a new contributor, Boatswain is now able to send GET and POST HTTP requests. It also received a new Scoreboard action that tracks numbers and optionally saves it into a file, so you can show your score on OBS Studio.
Boatswain now has a new user interface with 3 columns:
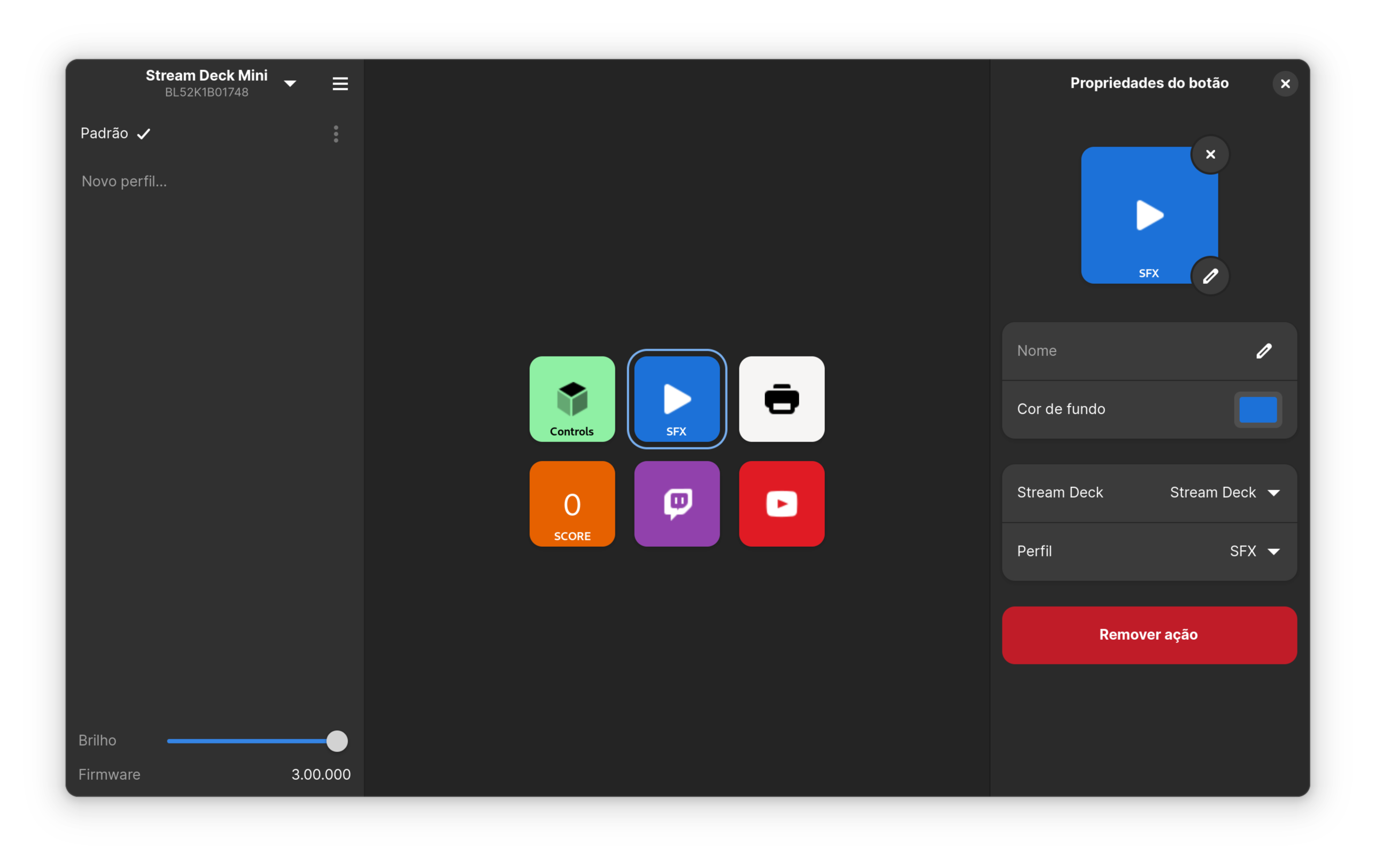
Recently, Boatswain gained the ability to trigger keyboard shortcuts on your host system as if it was a keyboard. This is not in any release yet, but I think it’ll cover some use cases as well.
Some people have asked for Elgato Stream Deck Plus support, but sadly I couldn’t convince Elgato to send me an engineering sample of that device, so I’m considering doing another targeted fundraising campaign on Ko-Fi. If you’re interested in that, please let me know.
OBS Studio
I’ve been able to contribute a lot to OBS Studio during 2023. Funnily, most of my contributions have been on the design front, more than coding. I am definitely not a designer, so it feels slightly odd to be contributing with that. But alas, here we are.
In 2023, I created the
obsproject/design
repository and pushed a variety of assets in there. It contains both the basic building blocks for the mockups (widgets, windows and dialogs, etc) and actual mockups, as well as various illustrations and assets.
I proposed a redesigned status bar in one of the mockups, and that was promptly implemented by a community member, and now is part of the OBS Studio 30.0 release.
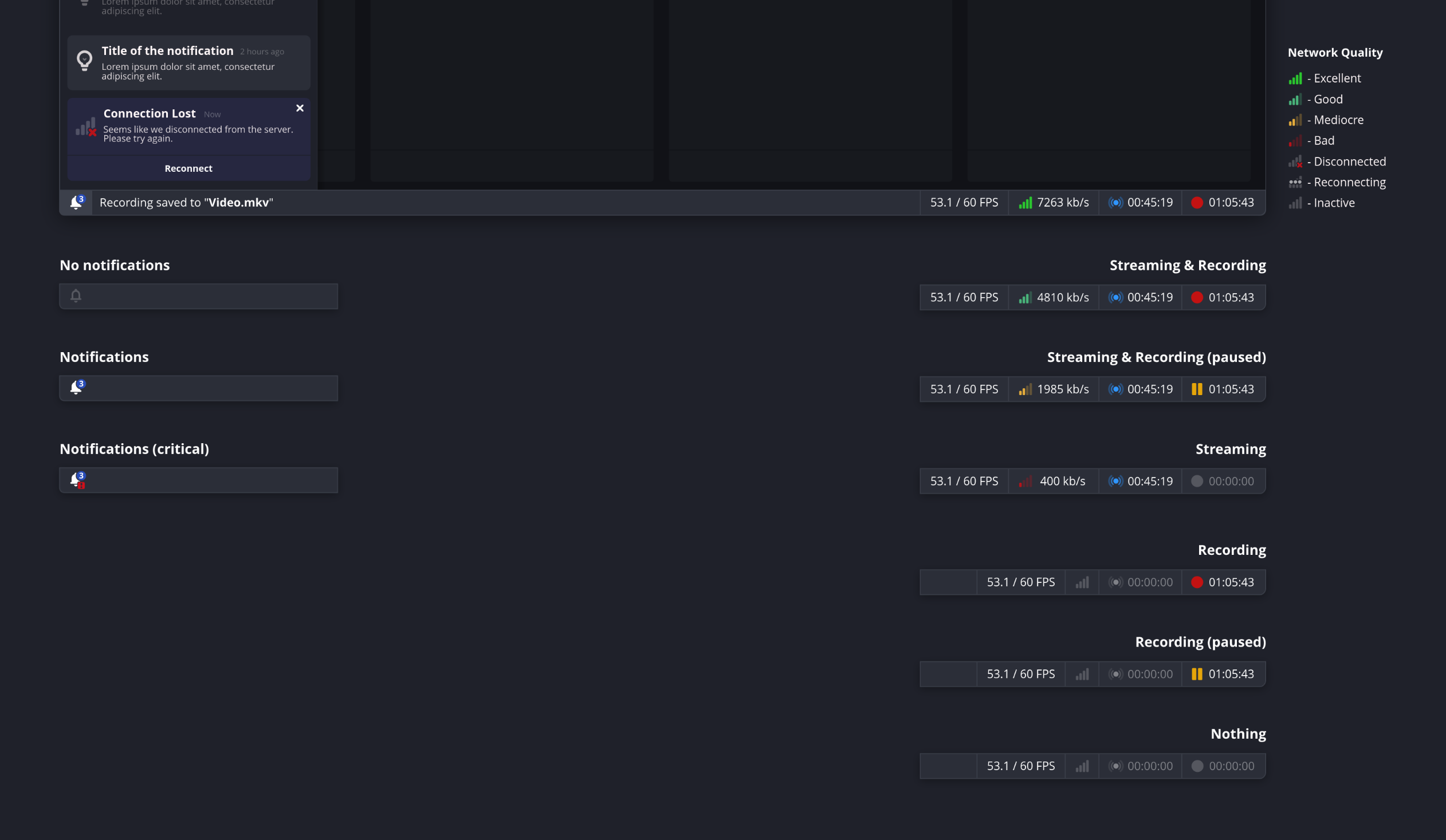
Thanks to the fantastic work of Warchamp7 and other contributors, the OBS Studio project now has an official color palette. This is an important milestone for the project, because so far, the colors not standardized and basically picked by eye.

To get a better sense of how these colors feel in practice, I’ve made a wavy background. I think it looks pretty, and certainly shows that there is a trend in the colors picked. They taste like the Yami style.

There’s a lot more but I’ll write an article about it on the OBS Studio blog.
On the coding front, most of my contributions during 2023 have been on code reviews, and making sure things are well maintained.
One big feature that just landed is the Camera portal & PipeWire based camera source. It’s still in beta, and is highly experimental, but people can start testing it and reporting bugs. I’ll probably write more about it later.
Side projects
In addition to contributing and maintaining existing projects, I also spent some time experimenting with different kinds of apps on a variety of problem domains.
Liveblast
In 2023, I started working on Liveblast, a GStreamer-based streaming app. My goals were threefold: learn a bit of Rust, learn about GStreamer, and understand the streaming problem domain a bit better.
For the brief moment I was experimenting with it, it did ripple through the stack; most notably, I added two
new
features
to GStreamer’s
glvideomixer
in order to support Liveblast’s use case better. I also
improved PipeWire’s
pipewiresrc
element
while working on Liveblast.
The project is stalled for now. I think one of the factors is that I found the maintenance cost of Rust dependencies too high, and progress too slow to release sufficient dopamine in my brain. It’s not abandoned though, I’m just not very motivated to work on it right now.
You can find Liveblast’s code here, if you’re interested in contributing .
Spiel
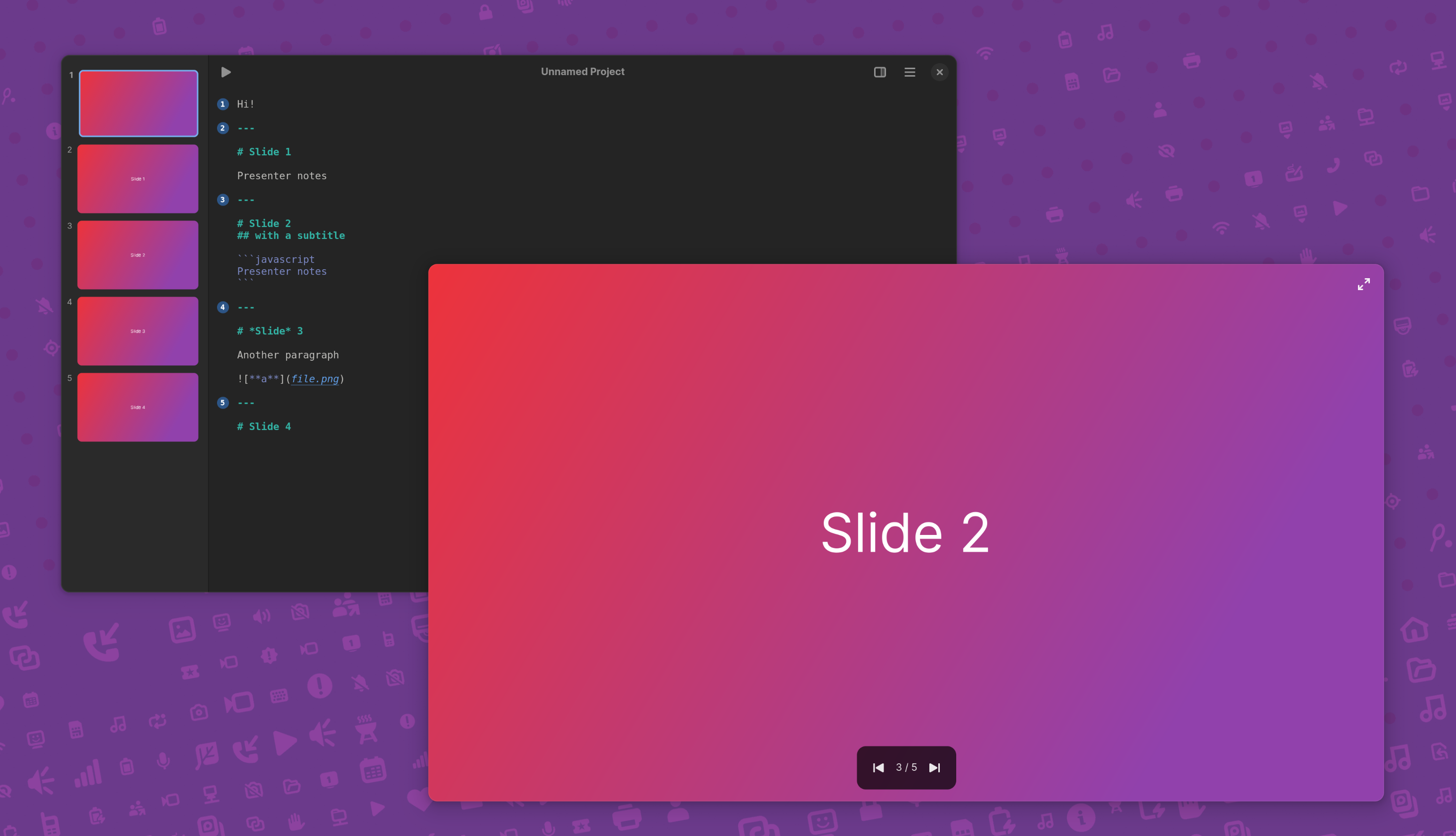
Back in 2021, I decided to do a talk by creating a libadwaita app instead of a traditional slide deck.
This stupid little project eventually evolved into a full blown presentation editor with static layouts, and then after Jakub’s suggestion, it shifted direction into a Markdown editor that generates slides automatically.
After three rewrites, the project is now shaping up into something I’m starting to enjoy. There is still a lot to do, and Spiel definitely is definitely not in a usable state right now, but there’s some potential.
My most immediate goals are adding a media gallery, so people can import and add fancy images to their talks; rename it to something else, since someone published another project called Spiel recently; add support for project themes; and more slide layouts, such as full size image and video, opening slides, etc.
You can find Spiel’s code here, if you’re interested in contributing .
Wastepaper

This one is a little experiment I’m doing with throwaway task lists. The pitch is to not have any kind of persistent task lists; you open the app, add your most immediate tasks, do them, mark them as complete, and begone.
There ain’t much to see, and it basically doesn’t work, but it’s fun

You can find Wastepaper’s code here, if you’re interested in contributing .
Luminen
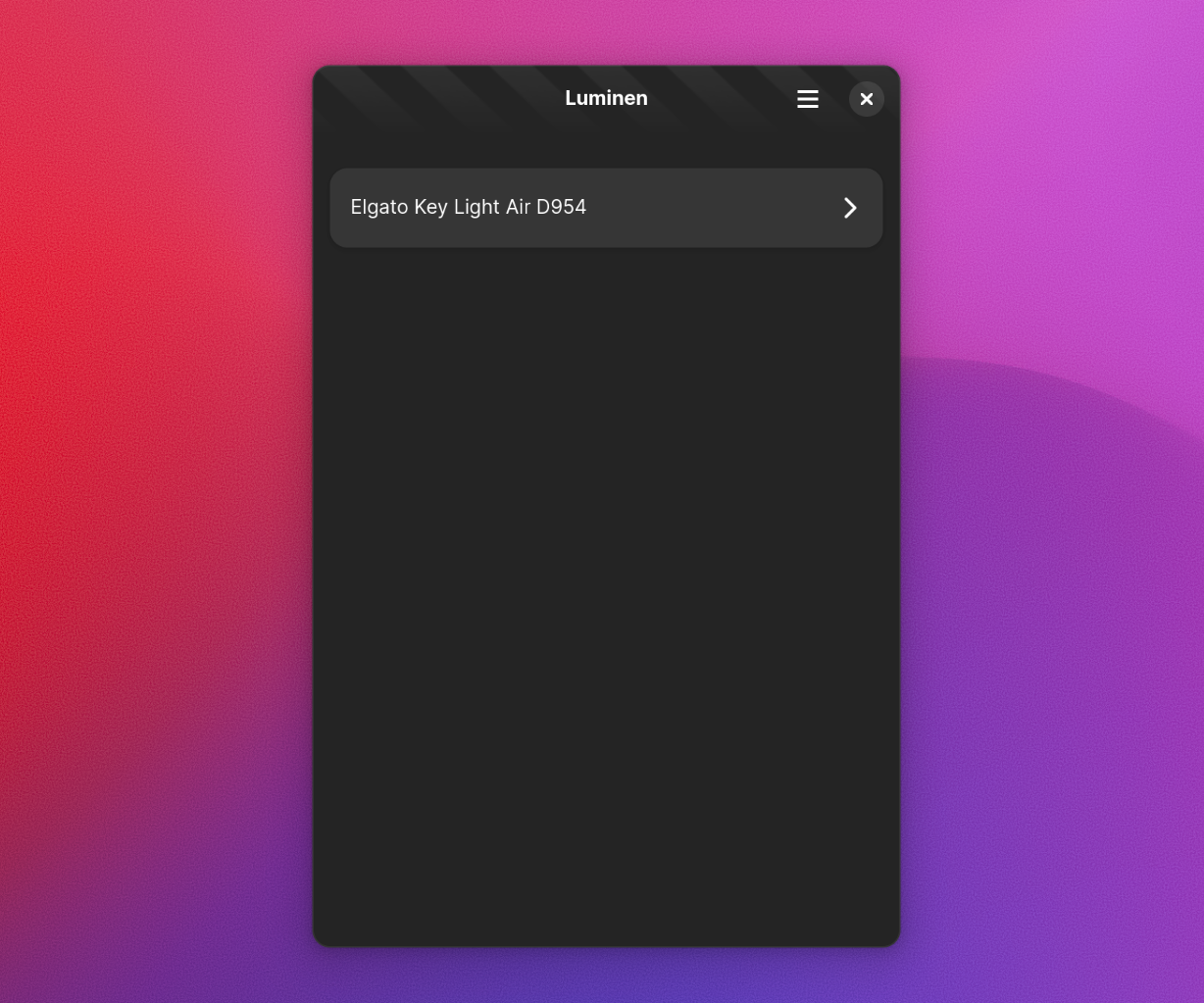
Luminen is a little app that allows controlling lights from Elgato. Right now it supports Key Elgato Light, Elgato Key Light Air, Elgato Key Light Mini, and Elgato Ring Light. It partially supports Elgato Light Stripe.
The project was made thanks to the generous sponsoring of my Ko-Fi supporters, who raised funds to acquire an Elgato Key Light Air (since, again, Elgato is not interested in sending any devices or engineering samples).
The project currently works, with the caveat that you need to engage with the light using the smartphone app first. I don’t know how to implement that using Wi-Fi or Avahi, if anyone knows, I’d love to learn about that.
You can find Luminen’s code here, if you’re interested in contributing .
Events
2023 was a travel-heavy year. In an online-by-default community like GNOME, it’s easy to forget how human bonds thrive when we’re physically together. Being together with other community members after such a long time was wonderful.
Linux App Summit

In April 2023, I participated in Linux App Summit in Brno. It was pretty cool. There were nice talks all around, but personally I enjoyed the castle and courtyard hackfests more.
The highlight for me was sitting right beside Bart and seeing the new Flathub website going to prod in real time, that was exciting.
GUADEC

GUADEC is always the conference I look forward the most every year, and it was no different this time. I think it was fantastic.
The Mutter & Shell crew did the traditional State of the Shell talk. It went well. It’s not every day nor everyone that is able to say “all extensions are broken” and still get the crowd to cheer and hype, but Florian did just that! ¹
There were nice talks about topics that interest me; the GTK status update was a nice recap of what happened; Carlos’ Codename “Emergence”: A RDF data synchronization framework was interesting too and got me thinking into the possibilities of RDF in my apps.
But the peaks of GUADEC, to me, were Jussi’s Let’s play a game of not adding options lighting talk, and Allan’s Communication matters: a talk about how to talk online .
The former just caught me off-guard, Jussi absolutely nailed the narrative there.
As for the Allan’s talk, I think the choice of topic was surgical given the difficult conversations within the community at the time. And it was incredibly useful material to me. I keep coming back to this talk to reabsorb what’s in there. I can only encourage everyone to go ahead, watch it, and see how it can be applied to you.
Ubuntu Summit

To end the year in a good tone, I was happy to attend Ubuntu Summit and give a talk about XDG Desktop Portal in there. I was absolutely scared of giving such a talk, and almost freaked out, but in the end it all went well (I hope!) and nice conversations branched off from it. Together with Marco and Matthias, we gave a nice round of updates about GNOME to the Ubuntu community as well.
It was a nice opportunity to see good friends again.
Life stuff
On a personal level, 2023 was tough. Between a head-first deep dive to hell during the first few months, uncomfortable situations all around the community, a flaming burnout, and the loss of a relative, it was pretty difficult to stay put. It made me realize how important it is to have a safety net of friends and family around you, no matter how physically close they are.
If it wasn’t for the fantastic friends in the GNOME community, a supportive partner, and lots of therapy, I don’t think I’d have continued my involvement with free software or even the tech space.
I think I owe an apology to all the people I hurt this year. I humbly do so now. Fortunately, things are in a better place now.
2023 was the year that I left the Endless OS Foundation, after 8 wonderful years there. Endless was my first employer, and I hold it dear to me. Right after that, I was fortunate to join the team working with the Sovereign Tech Found grant for GNOME.
My project officially ended December 2023, and it went relatively well. The scope of the USB portal project kept growing and changing as we learned about new constraints and whatnot, but I think I’m satisfied with the progress. I’ll continue pushing the USB portal forward independently, though admittedly with less available time.
Lastly, 2023 was the year I managed to upload my first original song ever. Very simple and unoriginal, honestly doesn’t sound good enough, but it’s… something, I guess.
What’s next in 2024
I took a little break last week (and, as I type this, I realize I forgot to roll some GNOME releases!) and now I feel energized to start the year. My goals for 2024 are:
- Try and produce more music. I want to release at least 2 more tracks this year.
- Release Spiel, possibly as a paid app in Flathub.
- Release Luminen, possibly as a paid app in Flathub.
- Work on other important portals. USB is a difficult one, but there’s a plethora of smaller, less disruptive portals that can be added and will have significant impact on the platform.
- Take more breaks and try and relax more. I’m not good at not working, and this has to change before another disaster happens.
- Enable more devices on Linux. Adding kernel-level support for Logitech lights is in my list already, but there can be more devices depending on how many people are willing to fund them.
- Stream more consistently, perhaps on a fixed schedule (difficult!).
A lot of what I do is entirely on my own free time. If you benefit from my contributions or simply enjoy what I do, consider supporting me on Ko-Fi or GitHub .
Last but not least…
I’m joining Igalia ! I’ll be working on the Browsers team, likely on WebKit-related tasks. I’m looking forward to that.
¹ – Chill out, this is just a little joke. Watch the talk and see what that was about
 – I think while developing Wayland-as-an-ecosystem we are now entrenched into narrow concepts of how a desktop should work. While discussing Wayland protocol additions, a lot of concepts clash, people from different desktops with different design philosophies debate the merits of those over and over again never reaching any conclusion (just as you will never get an answer out of humans whether sushi or pizza is the clearly superior food, or whether CSD or SSD is better). Some people want to use Wayland as a vehicle to force applications to submit to their desktop’s design philosophies, others prefer the smallest and leanest protocol possible, other developers want the most elegant behavior possible. To be clear, I think those are all very valid approaches.
– I think while developing Wayland-as-an-ecosystem we are now entrenched into narrow concepts of how a desktop should work. While discussing Wayland protocol additions, a lot of concepts clash, people from different desktops with different design philosophies debate the merits of those over and over again never reaching any conclusion (just as you will never get an answer out of humans whether sushi or pizza is the clearly superior food, or whether CSD or SSD is better). Some people want to use Wayland as a vehicle to force applications to submit to their desktop’s design philosophies, others prefer the smallest and leanest protocol possible, other developers want the most elegant behavior possible. To be clear, I think those are all very valid approaches.


 ︎
︎











{kind=link}
{kind=link}
{kind=link}