-
chevron_right
genma : Lifehacking - Création de tickets dans le Kanban Gitlab via l'API
genma • news.movim.eu / PlanetLibre • 6 January, 2021 • 13 minutes

Introduction
Il y a quelques années, je me suis initié à l'usage du Kanban ( Lifehacking - Kanban ) et j'ai utilisé pour de nombreux projets et suivi d'actions des Kanbans au sein de Gitlab ( Lifehacking - Gitlab, outil idéal ? ). Je continue d'utiliser le Kanban Gitlab : j'ai mes habitudes, je forme les personnes avec lesquelles je travaille sur les procédures et bonnes pratiques que j'ai mises en place sur les rédactions des tickets et leurs vie (suivi /traçabilité...).
Je me suis demandé comment il serait possible d'automatiser certaines choses dans l'usage du Kanban de Gitlab. Si vous utilisez Gitlab au quotidien, vous serez peut-être intéressés par son API. Elle vous permet, au travers de scripts dans le langage de votre choix, d'exécuter certaines tâches en lignes de commandes.
J'ai demandé à Brume, qui est en stage avec moi, de rédiger le présent billet de tutoriel de création de tickets dans le Kanban Gitlab via l'API de Gitlab. Voici donc le tutoriel.
Les Kanbans dans Gitlab ?
A chaque projet dans Gitlab est associé un Kanban permettant la gestion du projet. L'objectif n'est pas de présenter l'usage de ce Kanban (qui est assez intuitif mais aussi assez riche en fonctionnalités et complet).
Tutoriel de l'API de GitLab
L'API de Gitlab est une API REST. Elle fournit des fichiers JSON accessibles par liens, ainsi que la possibilité de réaliser des actions en donnant des paramètres GET, POST... : après le lien, vous pouvez rajouter ?argument=value.
Dans le navigateur, il n'y en a pas besoin, mais avec Curl, les requêtes doivent être suivies par ?access_token= ou précédées par —header "PRIVATE-TOKEN : ".
Accéder aux fichiers JSON issu d'un Kanban
Les requêtes suivantes sont uniquement des requêtes GET, il est donc possible de soit les ouvrir dans un navigateur soit avec Curl.
Pages d'un projet : https://gitlab-exemple.com/api/v4/projects/nom_du_projet
Chaque / entre le nom du mainteneur et le nom du projet doivent être remplacés par %2F. Remarquez également que /projects/ a été rajouté comparé au lien d'origine.
Boards (le Kanban) : https://gitlab-exemple.com/api/v4/projects/9/boards/2
Le nom du projet est remplacé par son ID, ici 9. 2 correspond à l'ID du board que nous voulons regarder. Les boards sont seulement des filtres de tickets, proposant un rendu plus visuel et qui permet de trouver les informations facilement. Accéder à un board via l'API ne permet que de voir la liste des filtres par label.
Tickets https://gitlab-exemple.com/api/v4/projects/9/issues
Il existe beaucoup d'arguments GET pour filter les tickets. Par exemple, pour filtrer les tickets par label, utilisez le l'argument labels=value (vous pouvrez ajouter plusieurs labels en les séparant par des virgules).
Actions via des requêtes sur les tickets
Les requêtes suivantes utilisent d'autre paramètres que GET. Le plus avisé est donc d'utiliser Curl.
Créer un ticket
curl --request POST --header "PRIVATE-TOKEN: " "https://gitlab-exemple.com/api/v4/projects/13/issues?&title=A%20Title&labels=To%20Do&description=test" Vous pouvez constater ici qu'il y a trois arguments : title, labels et description. Seul le titre est obligatoire. Il existe de nombreuses possibilités. Remarquez que les espaces doivent être remplacés par %20, sinon vous optiendrez une erreur 400.
Supprimer un ticket
curl --request DELETE --header "PRIVATE-TOKEN: " "https://gitlab-exemple.com/api/v4/projects/13/issues/2" 2 est l'IID (internal ID) du ticket que nous voulons supprimer. Vous pouvez l'obtenir dans la liste des tickets (ils sont triés par ordre de création).
Éditer un ticket
curl --request PUT --header "PRIVATE-TOKEN: " "https://gitlab-exemple.com/api/v4/projects/13/issues/6?title=Title%20Changed&add_labels=AAA,BBB,changed" Il existe beaucoup d'arguments pour éditer des tickets, comme : ![]() add_label, remove_labels et labels pour ajouter, supprimer ou réécrire entièrement la liste des labels ;
add_label, remove_labels et labels pour ajouter, supprimer ou réécrire entièrement la liste des labels ; ![]() title, description pour ajouter un titre ou une description ;
title, description pour ajouter un titre ou une description ; ![]() state_event=closed ou reopen pour fermer ou réouvrir un ticket.
state_event=closed ou reopen pour fermer ou réouvrir un ticket.
Un script d'exemple, en Python
Nous allons proposer et expliquer un script d'exemple, en Python, d'utilisation de cette API. Ce script permettra, pour un projet donné, de publier, éditer ou supprimer des issues.
Prérequis
Pour suivre cet exemple, vous aurez besoin de : ![]() avoir Python 3 installé sur votre machine ;
avoir Python 3 installé sur votre machine ; ![]() avoir un compte sur une instance GitLab ;
avoir un compte sur une instance GitLab ; ![]() créer un projet sur votre compte GitLab ;
créer un projet sur votre compte GitLab ; ![]() créér un token d'accès (décrit ci-dessous).
créér un token d'accès (décrit ci-dessous).
Se créer un token d'accès
Sur Gitlab, allez dans les paramètres de votre compte utilisateur. Allez dans l'onglet "Access Token". Entrez un nom, cochez au moins la case "api", et validez. Vous recevrez votre token. Pensez à le stocker, car il ne sera plus accessible par la suite et vous serez obligés de vous en re-créer un.
Bibliothèques utilisées
Requests est une bibliothèque qui permet de faire des requêtes HTML en Python, à la manière de Curl en Bash.
Utilisation :
import requests
headers = {'PRIVATE-TOKEN': "YOUR-TOKEN"}
r = requests.get(link, headers=headers) link est le lien de la page que l'on souhaite récupérer, `YOUR-TOKEN` votre token secret, et `get` le type de la requête. Il est possible d'utiliser d'autre paramètres comme `delete`, `post`, `put`...
r est un objet, contenant notamment : ![]() le code de retour de la requête, `r.status_code` ;
le code de retour de la requête, `r.status_code` ; ![]() le texte (du json dans notre cas) récupéré, `r.text`.
le texte (du json dans notre cas) récupéré, `r.text`.
Json permet tout simplement de parser et de récupérer des informations dans des JSON.
Utilisation :
import json
file = json.loads(file)
print(json[0]["username"]) file est le fichier ou texte que l'on veut utiliser, dans notre cas `r.text`. Il est possible d'extraire les éléments du json par clés ou index, comme dans l'exemple.
ConfigParser permet de lire un fichier de configuration dans un fichier `.ini`, et d'ajouter les valeurs à notre code.
Utilisation :
from configparser import ConfigParser
cfg = ConfigParser()
cfg.read('config.ini')
variable = cfg.get("section", "variable") Attention à bien vérifier que le fichier existe et que toutes les valeurs sont présentes à l'intérieur, pour éviter tout dysfonctionnement.
En premier, un objet `ConfigParser` est initialisé. Ensuite, on lui donne le fichier de configuration à lire, ici `config.ini`. Ce fichier utilise la syntaxe suivante :
[section]
variable=valeur Il est possible de rajouter autant de variables et de sections que l'on veut (avec des noms différents).
Pour récupérer la valeur d'une variable, on utilise donc `cfg.get`, en précisant la section et la variable.
Dans notre cas, utiliser un fichier de configuration est utile pour que l'utilisateur puisse renseigner une fois mais pas à chaque fois le lien de l'instance Gitlab, l'id de son projet et son token d'accès.
Urllib
`urllib` permet de remplacer tous les caractères spéciaux d'une chaîne de caractères, pour n'utiliser que des caractères autorisés dans les liens. Par exemple, les espaces ne sont pas autorisés, donc ils seront remplacés par `%20`. Certains caractères ont également une signification dans le lien (comme `&`, qui lie deux paramètres. Les remplacer permet d'éviter toute mauvaise interprétation de l'entrée de l'utilisateur.
Utilisation :
import urllib.parse
variable = urllib.parse.quote("Titre de mon issue"), safe='') Ici, `Titre de mon issue` deviendra `Titre%20de%20mon%issue`. Par défaut, `urllib.parse.quote` remplace tous les caractères spéciaux sauf le `/`. Nous souhaitons que ce caractère soit aussi remplacé, pour le fonctionnement de notre requête, alors nous rajoutons `safe=''` pour indiquer que même le `/` n'est pas un caractère sécurisé.
En plus de ces 4 bibliothèques, `datetime` et `os.path` on été utilisées, mais ne sont pas fondamentalement nécessaires dans la création d'un script autour de l'API de Gitlab.
Utilisation de l'API de Gitlab
Notre script Python va tout d'abord proposer un choix multiple, où l'utilisateur entrera un chiffre pour accéder aux fonctionnalités suivantes : ![]() créer une issue,
créer une issue, ![]() modifier une issue,
modifier une issue, ![]() supprimer une issue.
supprimer une issue.
À chacune de ces actions est liée une fonction utilisant l'API de Gitlab.
Pour accéder à cette API, il faut rajouter `/api/v4/` à la fin de l'url de votre instance Gitlab. Dans les requêtes suivantes, nous utiliserons ` https://gitlab-exemple.com` en exemple. Cela donne donc :
https://gitlab-exemple.com/api/v4/ Pour envoyer vos requêtes, vous pouvez utiliser la bibliothèque `requests` présentée au-dessus. Pensez bien à utiliser la bibliothèque `urllib` pour sécuriser et formater les entrées des utilisateurs que vous allez rajouter à vos liens.
Créer une issue
Pour créer une nouvelle issue, il faut utiliser la requête suivante :
POST https://gitlab-exemple.com/api/v4/projects/ID/issues/?title=TITRE&labels=LABEL1,LABEL2&description=DESCRIPTION Ici, `ID` est à remplacer par l'ID du projet. Nous utilisons les arguments `title`, `labels` et `description`. Il en existe beaucoup d'autres, et seul `title` est obligatoire. `TITRE`, `LABEL1,LABEL2`, `DESCRIPTION` sont donc à remplacer par vos propres valeurs.
La liste des arguments est disponible [ici]( https://docs.gitlab.com/ee/api/issues.html#new-issue ).
Modifier une issue
Pour modifier une issue, il faut utiliser la requête suivante :
PUT https://gitlab-exemple.com/api/v4/projects/ID/issues/IID/?title=TITRE&labels=LABEL1,LABEL2&description=DESCRIPTION Ici, `IID` est à remplacer par l'ID interne de l'issue. Le reste de la requête est semblable à la première.
Encore une fois, il existe de [nombreux arguments]( https://docs.gitlab.com/ee/api/issues.html#edit-issue ), pour modifier plein de détails comme le statut de l'issue, sa date d'échéance...
Supprimer une issue
Pour supprimer une issue, il faut utiliser la requête suivante :
DELETE https://gitlab-exemple.com/api/v4/projects/ID/issues/IID/ Récupérer des informations de l'API
L'API ne sert pas qu'à faire des actions, mais aussi à récupérer des informations. Voici quelques exemples :
https://gitlab-exemple.com/api/v4/projects/NOM-DU-PROJET https://gitlab-exemple.com/api/v4/projects/ID-DU-PROJET Récupérer la liste des issues d'un projet :
https://gitlab-exemple.com/api/v4/projects/ID-DU-PROJET À chaque fois, vous récupérerez un JSON à parser avec la librairie JSON présentée plus haut.
Script en Python utilisant l'API de Gitlab permettant de créer, modifier et supprimer des issues en ligne de commande.
Pour lancer le script, remplissez le fichier `config.ini` avec l'url de votre instance Gitlab, l'id de votre projet et votre token (générable depuis les paramètres utilisateurs), puis lancez :
./gitlab-cli.py Contenu du fichier config.ini
[configuration]
baselink=
project=
access_token= Code source du script ./gitlab-cli.py
#!/usr/bin/env python3
### BIBLIOTHÈQUES ###
import requests
import json
from configparser import ConfigParser
from datetime import datetime
import os.path
import urllib.parse
### COULEURS DE TEXTE ###
NC = "\\033[0m"
LB = "\\033[38;5;33m"
RED = "\\033[1;38;5;196m"
CY="\\033[38;5;81m"
### FONCTIONS ###
# Ajouter des labels
def lab_add():
labels = urllib.parse.quote(input("Please enter the labels you want to add: "), safe='')
if labels:
labels = "&add_labels={}".format(labels)
return labels
# Effacer des labels
def lab_delete():
labels = urllib.parse.quote(input("Please enter the labels you want to delete: "), safe='')
if labels:
labels = "&remove_labels={}".format(labels)
return labels
# Réécrire la liste des labels
def lab_rewrite():
labels = urllib.parse.quote(input("Please enter the new labels: "), safe='')
if labels:
labels = "&labels={}".format(labels)
return labels
def lab_keep():
return ""
# Fonction permettant de réaliser des choix multiples
def multiple_choice(choices):
value = 0
while value len(choices) :
try:
value = int(input("Enter a number: "))
except ValueError:
default()
continue
result = choices.get(value,default)()
return result
# Imprime les détails d'un ticket
def print_issue(link):
r = requests.get(link, headers=headers)
if r.status_code >= 400:
return 0
json_r = r.text
json_tk = json.loads(json_r)
date = datetime.strptime(json_tk["created_at"], "%Y-%m-%dT%H:%M:%S.%fZ")
date = datetime.strftime(date, "%Hh%M the %d %B %Y")
print("\\n{}Issue #{}{}{:>30} {}, at {}".format(LB, json_tk["iid"], NC, "Created by", json_tk["author"]["username"], date))
print("{}Title{}: {}".format(CY, NC, json_tk["title"]))
print("{}Description{}: {}".format(CY, NC, json_tk["description"]))
print("{}Labels{}: {}\\n".format(CY, NC, json_tk["labels"]))
return 1
# Imprime la liste des tickets
def print_list(link):
print("\\nList of issues:")
r = requests.get(link, headers=headers)
if r.status_code >= 400:
return 0
json_r = r.text
json_list = json.loads(json_r)
for issue in json_list:
print("#{}\\t{}".format(issue["iid"], issue["title"]))
# confirmer le choix du ticket. Fonction utilisée pour éditer et supprimer.
# Paramêtres : le lien du ticket et l'action à faire (dialogues)
def confirm_issue(link, action):
print_list(link)
iid = 0
code = 0
while iid boolean = "a"
try:
iid = int(input("\\nPlease enter the id of the issue you want to {}: ".format(action)))
except ValueError:
default()
continue
link_id = "{}{}".format(link, iid)
code = print_issue(link_id)
if not code :
print("{}Error:{} This issue doesn't exists. Please try again.".format(RED, NC))
continue
while boolean != "y" and boolean != "n":
boolean = input("Is it this ticket that you want to {}? (y/n) ".format(action))
return link_id
# Erreur avec l'API
def error_api(verb):
print("\\n{}Error:{} The issue has not been {}. Please verify that informations in 'config.ini' are valid.".format(RED, NC, verb))
exit(0)
# créer un ticket
def gl_create():
title = ""
while not title:
title = urllib.parse.quote(input("Please enter the title of your new issue (must not be empty) : ").strip(), safe='')
if not title:
print("{}Error:{} Title must not be empty. Please try again.".format(RED, NC))
desc = urllib.parse.quote(input("Please enter the description: "), safe='')
labels = urllib.parse.quote(input("Please enter labels, separated by commas: "), safe='')
link = "{}/issues?&title={}&labels={}&description={}".format(baselink, title, labels, desc)
try:
r = requests.post(link, headers=headers)
if r.status_code >= 400:
error_api("created")
print("Issue created!")
except:
error_api("created")
# éditer un ticket
def gl_edit():
link = "{}/issues/".format(baselink)
link = confirm_issue(link, "edit")
title = urllib.parse.quote(input("Please enter the new title (leave empty to change nothing): "), safe='')
desc = urllib.parse.quote(input("Please enter the new description (leave empty to change nothing): "), safe='')
if title:
title = "&title={}".format(title)
if desc:
desc = "&description={}".format(desc)
# menu des labels
print("\\nDo you want to:\\n{}1){} Add some labels\\t\\t{}2){} Delete some labels\\n{}3){} Rewrite all labels\\t\\t{}4){} Keep labels unchanged".format(LB, NC, LB, NC, LB, NC, LB, NC))
choices = {
1 : lab_add,
2 : lab_delete,
3 : lab_rewrite,
4 : lab_keep,
}
labels = multiple_choice(choices)
link = "{}/?{}{}{}".format(link, title, desc, labels)
try:
r = requests.put(link, headers=headers)
if r.status_code >= 400:
error_api("updated")
print("The issue had been updated, thank you!")
except:
error_api("updated")
# effacer un ticket
def gl_delete():
link = "{}/issues/".format(baselink)
link = confirm_issue(link, "delete")
try:
r = requests.delete(link, headers=headers)
if r.status_code >= 400:
error_api("deleted")
print("The issue had been deleted, thank you!")
except:
error_api("deleted")
def default():
print("{}Error:{} Wrong answer. Please try again.".format(RED, NC))
### MAIN ###
# effacer l'écran
print('\\033[2J')
if not os.path.isfile('config.ini'):
print("{}Error:{} config.ini file not found.".format(RED, NC))
exit(0)
# utilisation de config.ini
cfg = ConfigParser()
cfg.read('config.ini')
try:
baselink = "{}/api/v4/projects/{}".format(cfg.get("configuration", "baselink"), cfg.get("configuration", "project"))
headers = {'PRIVATE-TOKEN': cfg.get("configuration", "access_token")}
except:
print("{}Error:{} config.ini is incomplete. Please check that 'baselink', 'project' and 'access_token' fields exists.".format(RED, NC))
exit(0)
# premier menu
print("Hello! What do you want to do?\\n\\n{}1){} Create an issue\\t\\t{}2){} Edit an issue\\n{}3){} Delete an issue".format(LB, NC, LB, NC, LB, NC))
# dictionnaire des choix possibles
choices = {
1 : gl_create,
2 : gl_edit,
3 : gl_delete,
}
# interception du ^C
try:
multiple_choice(choices)
except (KeyboardInterrupt, SystemExit):
print("\\nGoodbye!")
exit(0) Captures d'écrans de l'exécution du script
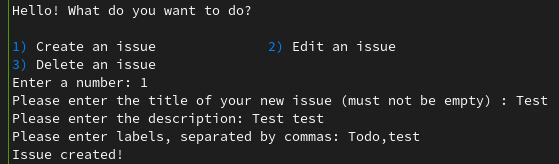
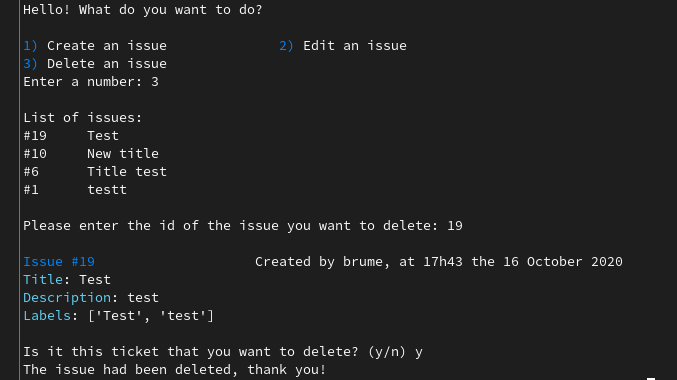
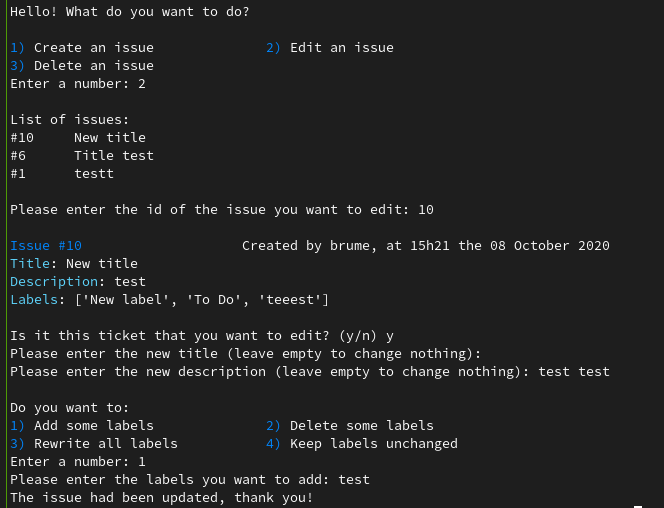
Conclusion
Voilà, avec tous ces éléments, vous devriez pouvoir vous débrouiller pour coder un script similaire. Gardez en tête que je n'ai présenté que quelques-unes des fonctionnalités de l'API de Gitlab, et qu'il en existe bien d'autres !
Enfin, voici un tutoriel https://git.42l.fr/brume/Script_API_Gitlab/src/branch/master/tutoriel-api-gitlab-bash.md , en français et en anglais, de l'utilisation de cette API en Bash.

Original post of genma .Votez pour ce billet sur Planet Libre .