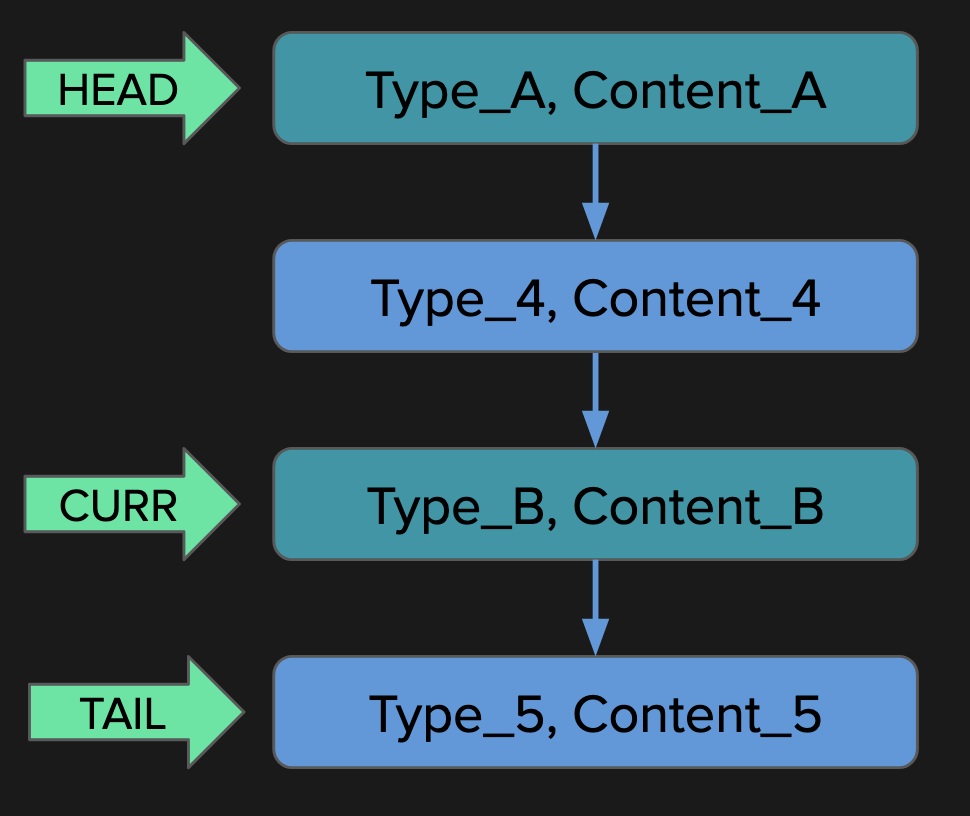
BEAM languages, such as Erlang and Elixir, offer a powerful tracing mechanism, and Erlang Doctor is built on top of it. It stores function calls and messages in an ETS table, which lowers the impact on the traced system, and enables querying and analysis of the collected traces. Being simple, always available and easy to use, it encourages you to pragmatically investigate system logic rather than guess about the reason for its behaviour.
This blog post is based on a talk I presented at the
FOSDEM 2024
conference.
Introduction
It is tough to figure out why a piece of code is failing, or how unknown software is working. When confronted with an error or other unusual system behaviour, we might search for the reason in the code, but it is often unclear what to look for, and tools like grep can give a large number of results. This means that there is some guessing involved, and the less you know the code, the less chance you have of guessing correctly. BEAM languages such as Erlang and Elixir include a tracing mechanism, which is a building block for tools like
dbg
,
recon
or
redbug
. They let you set up tracing for specific functions, capture the calls, and print them to the console or to a file. The diagram below shows the steps of such a typical tracing activity, which could be called
ad-hoc logging
, because it is like enabling logging for particular functions without the need for adding log statements to the code.

The first step is to choose the function (or other events) to trace, and it is the most difficult one, because usually, we don’t know where to start – for example, all we might know is that there is no response for a request. This means that the collected traces (usually in text format) often contain no relevant information, and the process needs to be repeated for a different function. A possible way of scaling this approach is to trace more functions at once, but this would result in two issues:
-
Traces are like logs, which means that it is very easy to get overwhelmed with the amount of data. It is possible to perform a text search, but any further processing would require data parsing.
-
The amount of data might become so large, that either structures like function arguments, return values and message contents become truncated, or the messages end up queuing up because of the I/O bottleneck.
The exact limit of this approach depends on the individual case, but usually, a rule of thumb is that you can trace one typical module, and collect up to a few thousand traces. This is not enough for many applications, e.g. if the traced behaviour is a flaky test – especially if it fails rarely, or if the impact of trace collection makes it irreproducible.
Tracing with Erlang Doctor
Erlang Doctor is yet another tool built on top of the Erlang tracer, but it has an important advantage – by storing the traces in an ETS table, it reduces the impact on the traced system (by eliminating costly I/O operations), while opening up the possibility of further processing and analysis of the collected traces.
Erlang Doctor is yet another tool built on top of the Erlang tracer, but it has an important advantage – by storing the traces in an ETS table, it reduces the impact on the traced system (by eliminating costly I/O operations), while opening up the possibility of further processing and analysis of the collected traces.
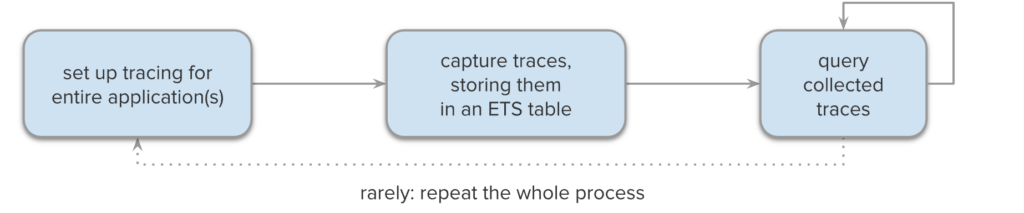
Being no longer limited by the amount of produced text, it scales up to millions of collected traces, and the first limit you might hit is the system memory. Usually it is possible to trace all modules in an application (or even a few applications) at once, unless it is under heavy load. Thanks to the clear separation between data acquisition and analysis, this approach can be called
ad-hoc instrumentation
rather than logging. The whole process has to be repeated only in rare situations, e.g. if wrong application was traced. Of course tracing production nodes is always risky, and not recommended, unless very strict limits are set up in Erlang Doctor.
Getting Started
Erlang Doctor is available at
https://github.com/chrzaszcz/erlang_doctor
. For Elixir, there is
https://github.com/chrzaszcz/ex_doctor
, which is a minimal wrapper around Erlang Doctor. Both tools have Hex packages (
erlang_doctor
,
ex_doctor
). You have a few options for installation and running, depending on your use case:
-
If you want it in your Erlang/Elixir shell right now, use the “firefighting snippets” provided in the Hex or GitHub docs. Because Erlang Doctor is just one module (and ExDoctor is two), you can simply download, compile, load and start the tool with a one-liner.
-
For development, it is best to have it always at hand by initialising it in your
~/.erlang
or
~/.iex.exs
files. This way it will be available in all your interactive shells, e.g.
rebar3 shell
or
iex -S mix
.
-
For easy access in your release, you can include it as a dependency of your project.
Basic usage
The following examples are in Erlang, and you can run them yourself – just clone
erlang_doctor
, compile it, and execute
rebar3 as test shell
. Detailed examples for both Erlang and Elixir are provided in the Hex Docs (
erlang_doctor
,
ex_doctor
). The first step is to start the tool:
1> tr:start().
{ok,<0.86.0>}
There is also
tr:start/1
with additional
options
. For example,
tr:start(#{limit => 10000})
would stop tracing, when there are 10 000 traces in the ETS table, which provides a safety valve against memory consumption.
Trace collection
Having started the Erlang Doctor, we can now trace selected modules – here we are using a test suite from Erlang Doctor itself:
2> tr:trace([tr_SUITE]).
ok
The
tr:trace/1
function accepts a list of modules or
{Module, Function, Arity}
tuples. Alternatively, you can provide a map of
options
to trace specific processes or to enable message tracing. You can also trace entire applications, e.g.
tr:trace_app(your_app)
or
tr:trace_apps([app1, app2])
.
Let’s trace the following function call. It calculates the factorial recursively, and sleeps for 1 ms before each step:
3> tr_SUITE:sleepy_factorial(3).
6
It’s a good practice to stop tracing as soon as you don’t need it anymore:
4> tr:stop_tracing().
ok
Trace analysis
The collected traces are accumulated in an ETS table (default name:
trace
). They are stored as
tr
records, and to display them, we need to load the record definitions:
5> rr(tr).
[node,tr]
If you don’t have many traces, you can just list all of them:
6> tr:select().
[#tr{index = 1, pid = <0.175.0>, event = call, mfa = {tr_SUITE,sleepy_factorial,1},
data = [3], ts = 1559134178217371, info = no_info},
#tr{index = 2, pid = <0.175.0>, event = call, mfa = {tr_SUITE,sleepy_factorial,1},
data = [2], ts = 1559134178219102, info = no_info},
#tr{index = 3, pid = <0.175.0>, event = call, mfa = {tr_SUITE,sleepy_factorial,1},
data = [1], ts = 1559134178221192, info = no_info},
#tr{index = 4, pid = <0.175.0>, event = call, mfa = {tr_SUITE,sleepy_factorial,1},
data = [0], ts = 1559134178223107, info = no_info},
#tr{index = 5, pid = <0.175.0>, event = return, mfa = {tr_SUITE,sleepy_factorial,1},
data = 1, ts = 1559134178225146, info = no_info},
#tr{index = 6, pid = <0.175.0>, event = return, mfa = {tr_SUITE,sleepy_factorial,1},
data = 1, ts = 1559134178225153, info = no_info},
#tr{index = 7, pid = <0.175.0>, event = return, mfa = {tr_SUITE,sleepy_factorial,1},
data = 2, ts = 1559134178225155, info = no_info},
#tr{index = 8, pid = <0.175.0>, event = return, mfa = {tr_SUITE,sleepy_factorial,1},
data = 6, ts = 1559134178225156, info = no_info}]
The
index
field is auto-incremented, and
data
contains an argument list or a return value, while
ts
is a timestamp in microseconds. To select specific fields of matching records, use
tr:select/1
, providing a selector function, which is passed to
ets:fun2ms/1
.
7> tr:select(fun(#tr{event = call, data = [N]}) -> N end).
[3, 2, 1, 0]
You can use
tr:select/2
to further filter the results by searching for a specific term in
data
. In this simple example we search for the number
2
:
8> tr:select(fun(T) -> T end, 2).
[#tr{index = 2, pid = <0.395.0>, event = call, mfa = {tr_SUITE,sleepy_factorial,1},
data = [2], ts = 1705475521744690, info = no_info},
#tr{index = 7, pid = <0.395.0>, event = return, mfa = {tr_SUITE,sleepy_factorial,1},
data = 2, ts = 1705475521750454, info = no_info}]
This is powerful, as it searches all nested tuples, lists and maps, allowing you to search for arbitrary terms. For example, even if your code outputs something like “Unknown error”, you can pinpoint the originating function call. There is a similar function
tr:filter/1
, which filters all traces with a predicate function (this time not limited by
fun2ms
). In combination with
tr:contains_data/2
, you can get the same result as above:
9> Traces = tr:filter(fun(T) -> tr:contains_data(2, T) end).
[#tr{index = 2, pid = <0.395.0>, event = call, mfa = {tr_SUITE,sleepy_factorial,1},
data = [2], ts = 1705475521744690, info = no_info},
#tr{index = 7, pid = <0.395.0>, event = return, mfa = {tr_SUITE,sleepy_factorial,1},
data = 2, ts = 1705475521750454, info = no_info}]
There is also
tr:filter/2
, which can be used to search in a different table than the current one – or in a list. As an example, let’s get only function calls from
Traces
returned by the previous call:
10> tr:filter(fun(#tr{event = call}) -> true end, Traces).
[#tr{index = 2, pid = <0.395.0>, event = call, mfa = {tr_SUITE,sleepy_factorial,1},
data = [2], ts = 1705475521744690, info = no_info}]
To find the tracebacks (stack traces) for matching traces, use
tr:tracebacks/1
:
11> tr:tracebacks(fun(#tr{data = 1}) -> true end).
[[#tr{index = 3, pid = <0.395.0>, event = call, mfa = {tr_SUITE,sleepy_factorial,1},
data = [1], ts = 1705475521746470, info = no_info},
#tr{index = 2, pid = <0.395.0>, event = call, mfa = {tr_SUITE,sleepy_factorial,1},
data = [2], ts = 1705475521744690, info = no_info},
#tr{index = 1, pid = <0.395.0>, event = call, mfa = {tr_SUITE,sleepy_factorial,1},
data = [3], ts = 1705475521743239, info = no_info}]]
Note, that by specifying
data = 1
, we are only matching return traces, as call traces always have a list in
data
. Only one traceback is returned, starting with a call that returned 1. What follows is the stack trace for this call. There was a second matching traceback, but it wasn’t shown, because whenever two tracebacks overlap, the longer one is skipped. You can change this with
tr:tracebacks/2
, providing
#{output => all})
as the second argument. There are more
options
available, allowing you to specify the queried table/list, the output format, and the maximum amount of data returned. If you only need one traceback, you can call
tr:traceback/1
or
tr:traceback/2
.
Additionally, it is possible to pass a
tr
record (or an index) directly to
tr:traceback/1
.
To get a list of traces between each matching call and the corresponding return, use
tr:ranges/1
:
12> tr:ranges(fun(#tr{data = [1]}) -> true end).
[[#tr{index = 3, pid = <0.395.0>, event = call, mfa = {tr_SUITE,sleepy_factorial,1},
data = [1], ts = 1705475521746470, info = no_info},
#tr{index = 4, pid = <0.395.0>, event = call, mfa = {tr_SUITE,sleepy_factorial,1},
data = [0], ts = 1705475521748499, info = no_info},
#tr{index = 5, pid = <0.395.0>, event = return, mfa = {tr_SUITE,sleepy_factorial,1},
data = 1, ts = 1705475521750451, info = no_info},
#tr{index = 6, pid = <0.395.0>, event = return, mfa = {tr_SUITE,sleepy_factorial,1},
data = 1, ts = 1705475521750453, info = no_info}]]
There is also
tr:ranges/2
with
options
, allowing to set the queried table/list, and to limit the depth of nested traces. In particular, you can use
#{max_depth => 1}
to get only the top-level call and the corresponding return. If you only need the first range, use
tr:range/1
or
tr:range/2
.
Last but not least, you can get a particular trace record with
tr:lookup/1
, and replay a particular function call with
tr:do/1
:
13> T = tr:lookup(1).
#tr{index = 1, pid = <0.175.0>, event = call, mfa = {tr_SUITE,sleepy_factorial,1},
data = [3], ts = 1559134178217371, info = no_info}
14> tr:do(T).
6
This is useful e.g. for checking if a bug has been fixed without running the whole test suite, or to reproduce an issue while capturing further traces. This function can be called with an index as the argument:
tr:do(1)
.
Quick profiling
Although there are dedicated
profiling tools
for Erlang, such as
fprof
and
eprof
, you can use Erlang Doctor to get a hint about possible bottlenecks and redundancies in your system with function call statistics. One of the advantages is that you already have the traces collected from your system, so you don’t need to trace again. Furthermore, tracing only specific modules gives you much simpler output, that you can easily read and process in your Erlang shell.
Call statistics
To get statistics of function call times, you can use
tr:call_stat/1
, providing a function that returns a key by which the traces will be aggregated. The simplest use case is to get the total number of calls and their time. To do this, we group all calls under one key, e.g.
total
:
15> tr:call_stat(fun(_) -> total end).
#{total => {4,7216,7216}}
The tuple
{4,7216,7216}
means that there were four calls in total with an accumulated time of 7216 microseconds, and the “own” time was also 7216 μs – this is the case because we have aggregated all traced functions. To see different values, let’s group the stats by the function argument:
16> tr:call_stat(fun(#tr{data = [N]}) -> N end).
#{0 => {1,1952,1952}, 1 => {1,3983,2031}, 2 => {1,5764,1781}, 3 => {1,7216,1452}}
Now it is apparent that although
sleepy_factorial(3)
took 7216 μs, only 1452 μs were spent in the function itself, and the remaining 5764 μs were spent in the nested calls. To filter out unwanted function calls, just add a guard:
17> tr:call_stat(fun(#tr{data = [N]}) when N < 3 -> N end).
#{0 => {1,1952,1952}, 1 => {1,3983,2031}, 2 => {1,5764,1781}}
There are additional utilities:
tr:sorted_call_stat/1
and
tr:print_sorted_call_stat/2
, which gives you different output formats.
Call tree statistics
If your code is performing the same operations very often, it might be possible to optimise it. To detect such redundancies, you can use
tr:top_call_trees/0
, which detects complete call trees that repeat several times, where corresponding function calls and returns have the same arguments and return values, respectively. As an example, let’s trace a call to a function which calculates the 4th element of the Fibonacci sequence recursively. The
trace
table should be empty, so let’s clean it up first:
18> tr:clean().
ok
19> tr:trace([tr_SUITE]).
ok
20> tr_SUITE:fib(4).
3
21> tr:stop_tracing().
ok
Now it is possible to print the most time-consuming call trees that repeat at least twice:
22> tr:top_call_trees().
[{13, 2, #node{module = tr_SUITE,function = fib, args = [2],
children = [#node{module = tr_SUITE, function = fib, args = [1],
children = [], result = {return,1}},
#node{module = tr_SUITE, function = fib, args = [0],
children = [], result = {return,0}}],
result = {return,1}}},
{5, 3, #node{module = tr_SUITE,function = fib, args = [1],
children = [], result = {return,1}}}]
The resulting list contains tuples
{Time, Count, Tree}
where
Time
is the accumulated time (in microseconds) spent in the
Tree
, and
Count
is the number of times the tree repeated. The list is sorted by
Time
, descending. In the example,
fib(2)
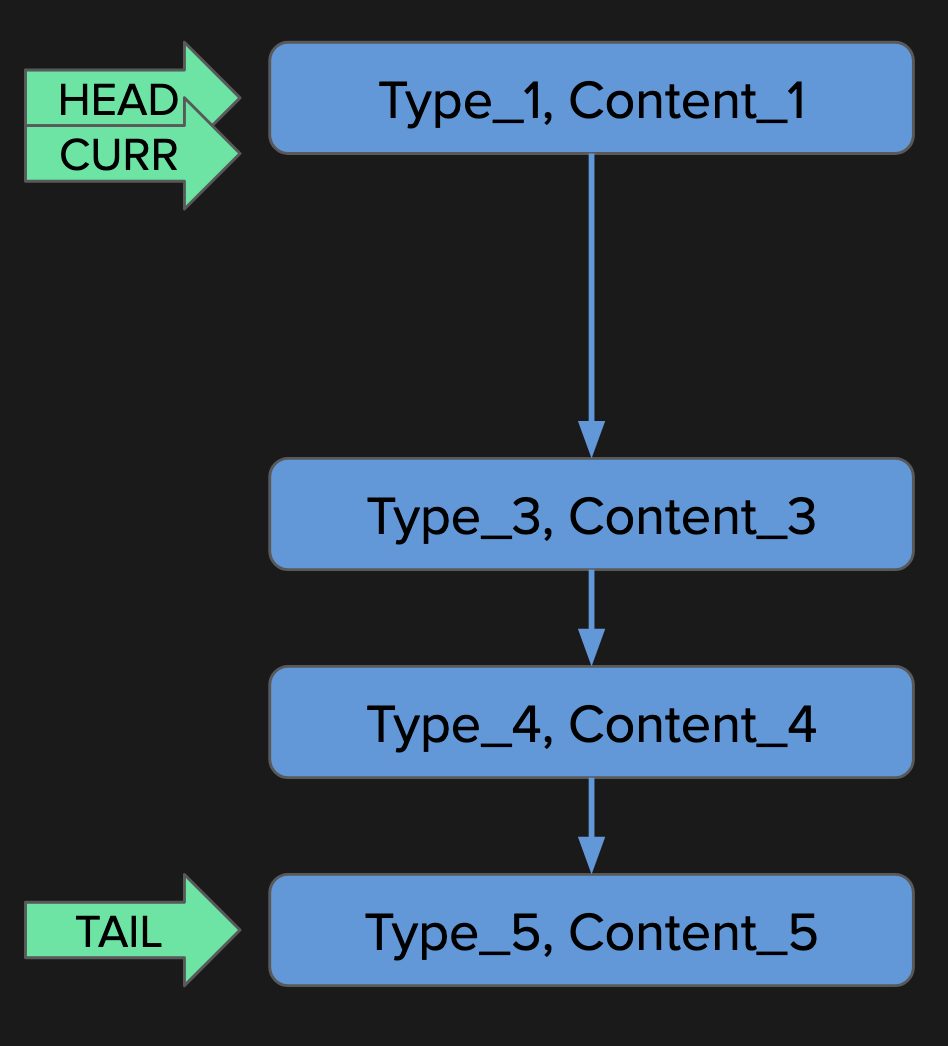
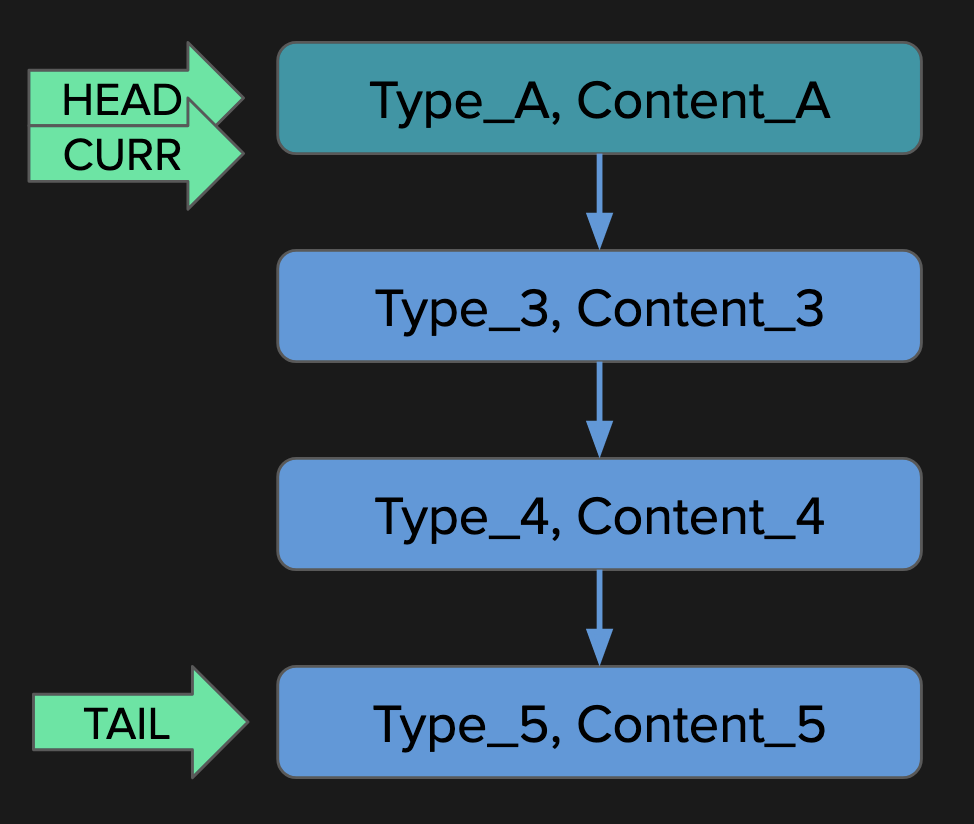
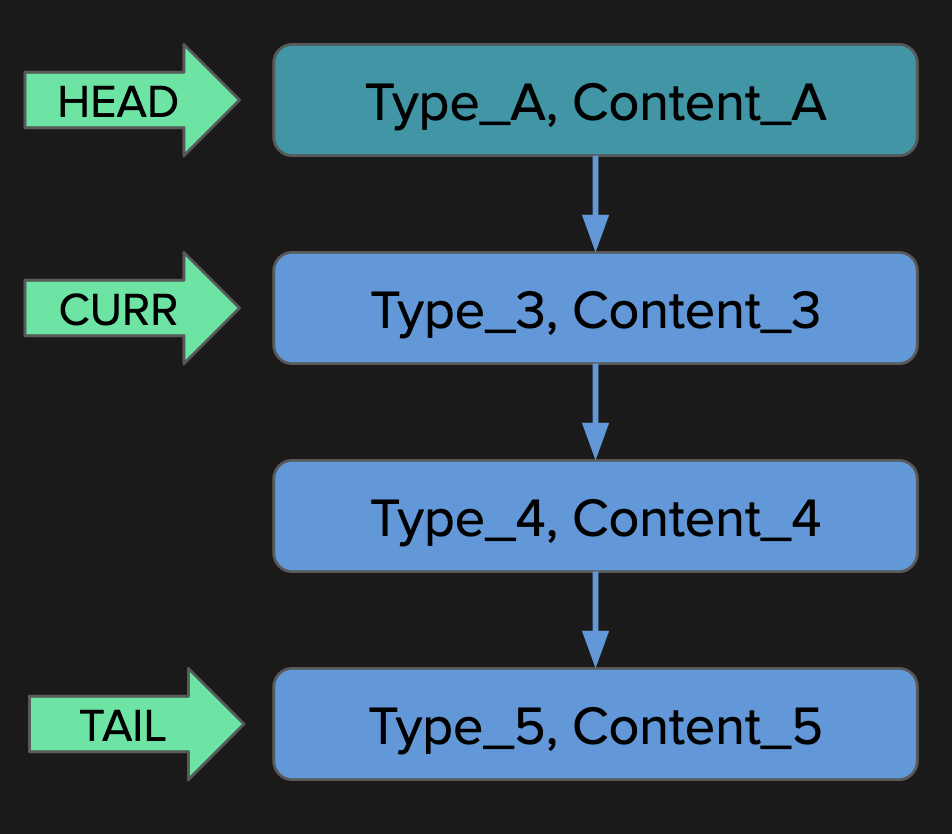
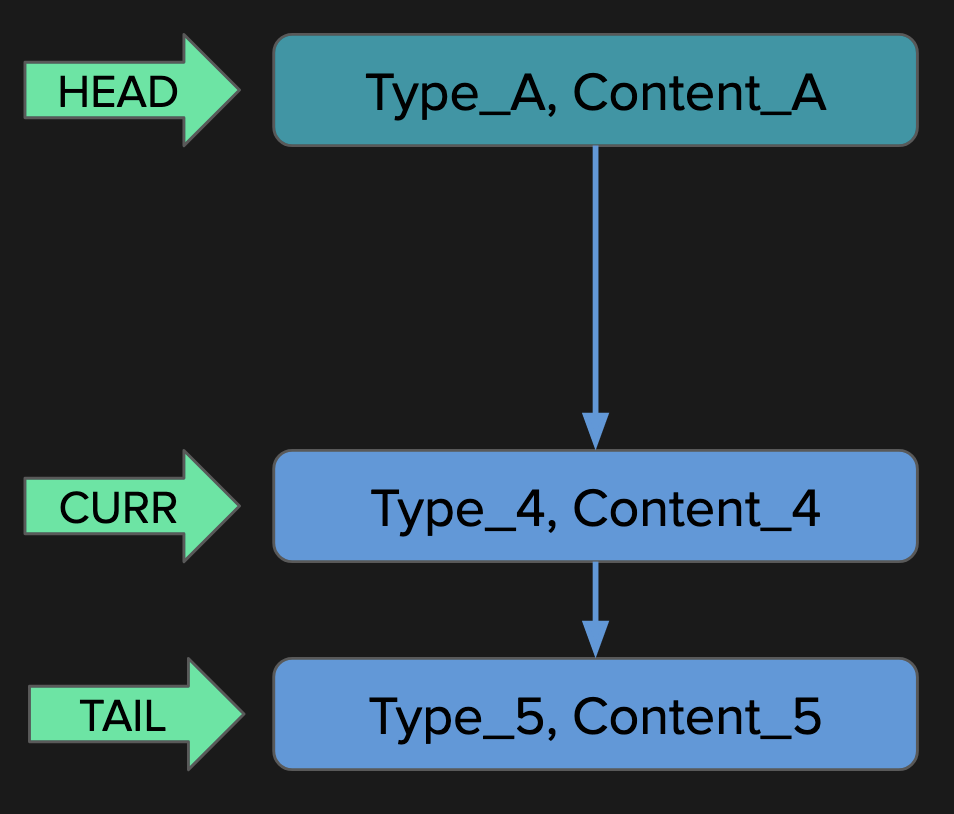
was called twice, which already shows that the recursive implementation is suboptimal. You can see the two repeating subtrees in the call tree diagram:
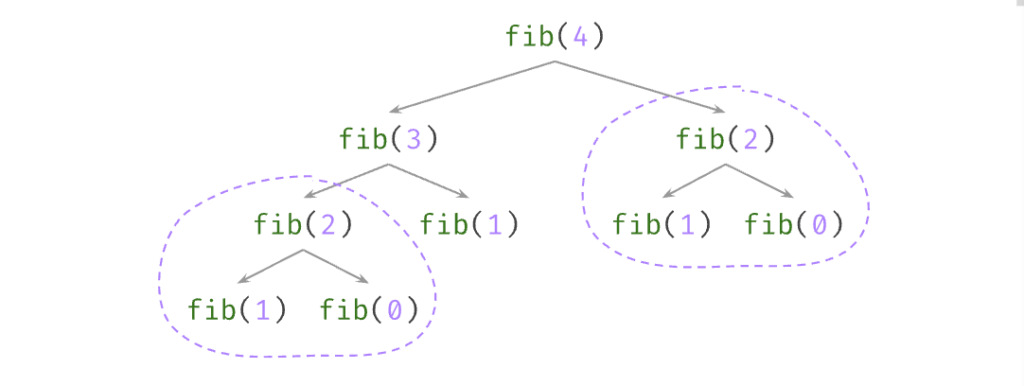
The second listed tree consists only of
fib(1)
, and it was called three times. There is also
tr:top_call_trees/1
with
options
, allowing customisation of the output format – you can set the minimum number of repetitions, maximum number of presented trees etc.
ETS table manipulation
To get the current table name, use
tr:tab/0
:
23> tr:tab().
trace
To switch to a new table, use
tr:set_tab/1
. The table need not exist.
24> tr:set_tab(tmp).
ok
Now you can collect traces to the new table without changing the original one. You can dump the current table to file with
tr:dump/1
– let’s dump the
tmp
table:
25> tr:dump("tmp.ets").
ok
In a new Erlang session, you can load the data with
tr:load/1
. This will set the current table name to
tmp
. Finally, you can remove all traces from the ETS table with
tr:clean/0
. To stop Erlang Doctor, just call
tr:stop/0
.
Summary
Now you have an additional utility in your Erlang/Elixir toolbox, which you can try out whenever you need to debug an issue or learn about unknown or unexpected system behaviour. Just remember to be extremely cautious when using it in a production environment. If you have any feedback, please provide it on GitHub, and if you like the tool, consider giving it a star.
The post
Guess Less with Erlang Doctor
appeared first on
Erlang Solutions
.
chevron_right